《深入理解计算机系统》第3版课本笔记(1—6章)
深入理解计算机系统
第1章 计算机系统漫游
1.1 信息就是位+上下文
字节
- 源程序实际上就是一个由值0和1组成的位(又称为比特)序列,8个位被组织成一组,称为
字节。 - 大部分的现代计算机系统都使用ASCII标准来表示文本字符,这种方式实际上就是用一个唯一的单字节大小的整数值来表示每个字符。
文本文件和二进制文件
- 像hello.c这样只由ASCII字符构成的文件称为
文本文件,所有其他文件都称为二进制文件。
1.2 程序被其他程序翻译成不同的格式
- 为了在系统上运行hello.c程序,每条C语句都必须被其他程序转化为一系列低级
机器语言指令。然后这些指令按照一种称为可执行目标程序的格式打好包,并以二进制磁盘文件的形式存放起来。目标程序也被称为可执行目标文件。
编译
-
执行这四个阶段的程序(预处理器、编译器、汇编器、链接器)一起构成了编译系统(compilation system)。
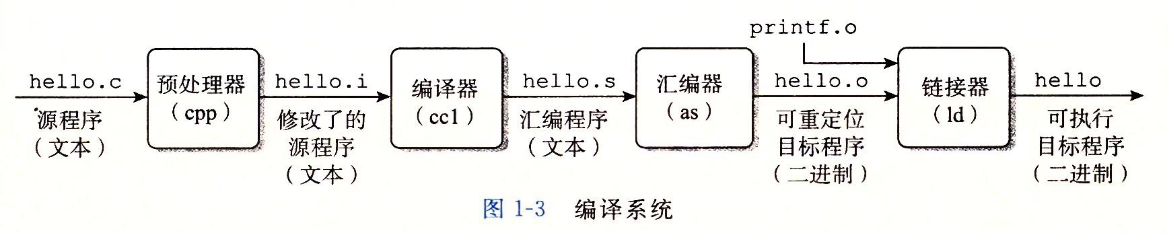
预处理阶段。预处理器(cpp)根据以字符#开头的命令,修改原始的C程序。(gcc -E test.c -o test.i)编译阶段。编译器(ccl)将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。(gcc -S test.i -o test.s)汇编阶段。接下来,汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序(relocatable object program)的格式,并将结果保存在目标文件hello.o中。(gcc -c test.s -o test.o)链接阶段。printf函数存在于一个名为printf.o的单独的预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的hello.o的程序中。链接器(ld)就负责处理这种合并。(gcc test.o -o test)
1.3 了解编译系统如何工作是大有益处的
1.4 处理器读并解释储存在内存中的指令
shell
- shell是一个命令解释器,它输出一个提示符,等待输入一个命令行,然后执行这个命令。如果该命令的第一个单词不是内置的shell命令,那么shell就会假设这是一个可执行文件的名字,它将加载并运行这个文件。
1.4.1 系统的硬件组成
总线
- 通常总线被设计成传输定长的字节块,也就是
字(word)。字中的字节数(即字长)是一个基本的系统参数,各个系统中都不尽相同。
I/O设备
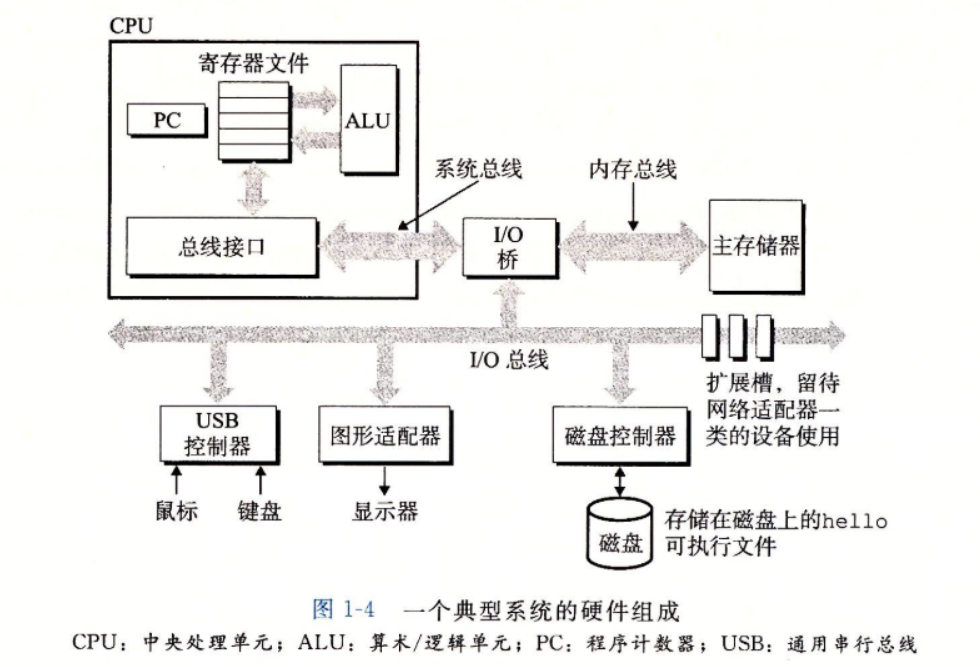
主存
- 主存是一个临时存储设备,在处理器执行程序时,用来存放程序和程序处理的数据。
处理器
-
中央处理单元(CPU),简称处理器,是解释(或执行)存储在主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器。在任何时刻,PC都指向主存中的某条机器语言指令(即含有该条指令的地址)。
-
寄存器文件是一个小的存储设备,由一些单个字长的寄存器组成,每个寄存器都有唯一的名字。ALU计算新的数据和地址值。
-
CPU在指令的要求下可能会执行这些操作:

1.4.2 运行hello程序
1.5 高速缓存至关重要
1.6 存储设备形成层次结构
一个存储器层次结构的示例
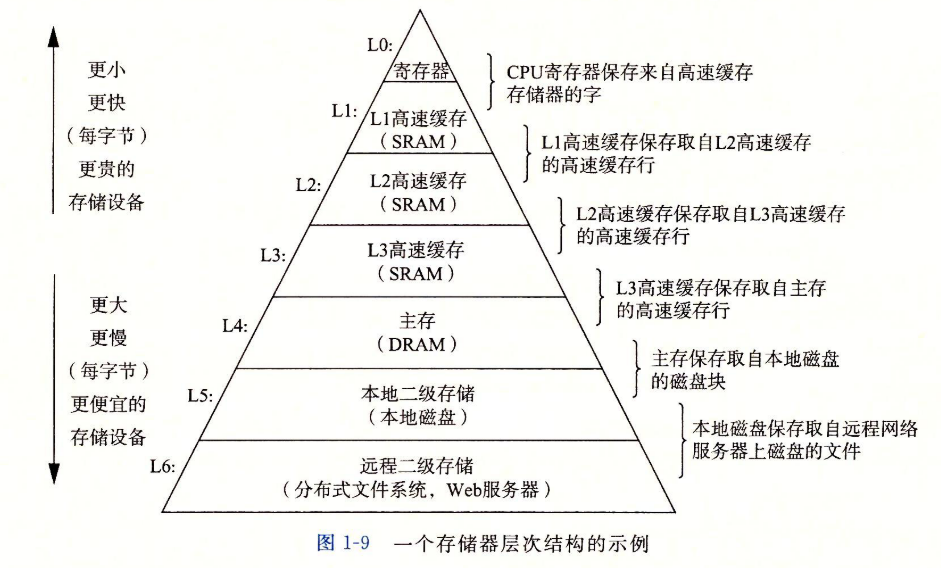
- 存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存。
1.7 操作系统管理硬件
计算机系统的分层视图

- 我们可以把操作系统看作是应用程序与硬件之前插入的一层软件。
操作系统提供的抽象表示
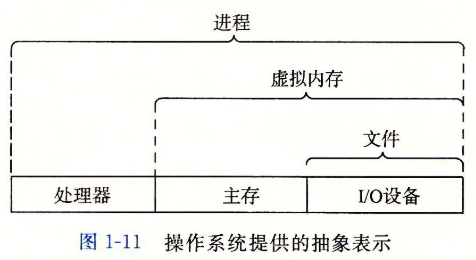
- 操作系统由两个基本功能:(1)防止硬件被失控的应用程序滥用;(2)向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备。
- 文件是对I/O设备的抽象表示,虚拟内存是对主存和硬盘I/O设备的抽象表示,进程则是对处理器、主存和I/O设备的抽象表示。
1.7.1 进程
进程是操作系统对一个正在运行的程序的一种抽象。
进程的上下文切换

1.7.2 线程
- 一个进程实际上可以又多个称为
线程的执行单元组成,每个线程都运行在进程的上下文中,并共享同样的代码和全局数据。
1.7.3 虚拟内存
虚拟地址空间
-
每个进程看到的内存都是一致的,称为
虚拟地址空间。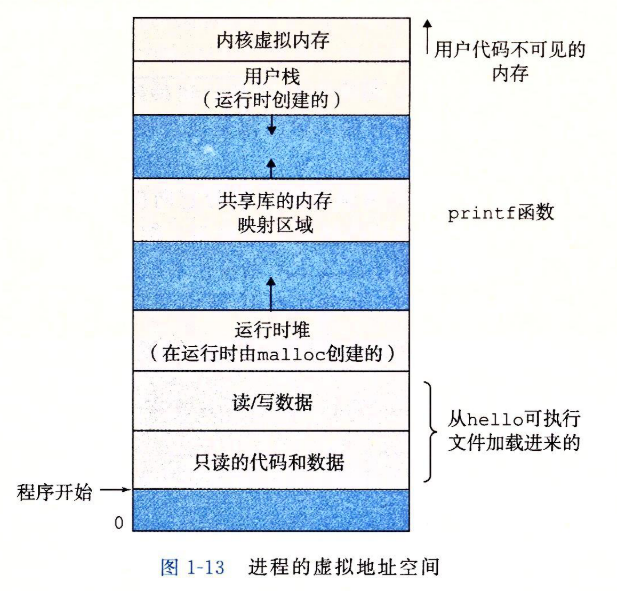
1.7.4 文件
- 文件就是字符序列。
1.8 系统之间利用网络通信
1.9 重要主题
1.9.1 Amdahl定律

1.9.2 并发和并行
- 并发(concurrency)是一个通用的概念,指一个同时具有多个活动的系统;而术语并行(parallelism)指的是用并发来使一个系统运行得更快。
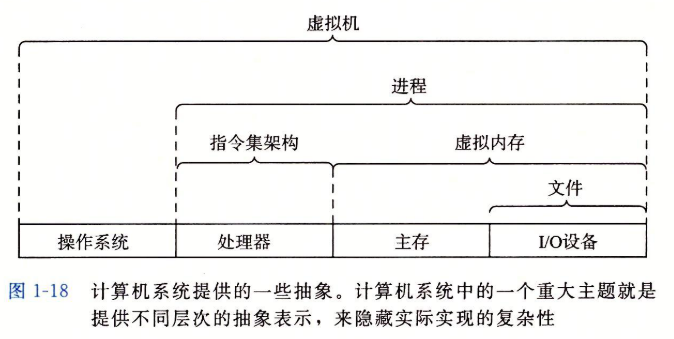
1.9.3 计算机系统中抽象的重要性
文件是多I/O设备的抽象,虚拟内存是对程序存储器的抽象,进程是对一个正在运行的程序的抽象,虚拟机是整个计算机的抽象,包括存储系统,处理器和程序。
第2章 信息的表示和处理
- 整数的表示虽然只能编码一个相对较小的数值范围,但是这种表示是精确的;而浮点数虽然可以编码一个较大的数值范围,但是这种表示只是近似的。
2.1 信息存储
- 大多数计算机使用8位的块,或者字节(byte),作为最小的可寻址的内存单位。
2.1.1 十六进制表示法
2.1.2 字数据大小
字长
- 每台计算机都有一个字长(word size),指明指针数据的标称大小(nominal size)。
- 对于一个字长为位的机器而言,虚拟地址的范围为~,程序最多访问个字节。
向后兼容
- 当程序prog.c用如下伪指令编译后
linux> gcc -m32 prog.c,该程序就可以在32位或64位机器上正确运行。 - 另一方面,若程序用下述伪指令编译
linux> gcc -m64 prog.c,那就只能在64位机器上运行。
2.1.3 寻址和字节顺序
- 在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所用字节中最小的地址。
小端法和大端法
-
最低有效字节在最前面的方式,称为小端法(little endian)。
-
最高有效字节在最前面的方式,称为大端法(big endian)。

-
一旦选择了特定操作系统,那么字节顺序也就固定下来。
2.1.4 表示字符串
- C语言中字符串被编码为一个以null(其值为0)字符结尾的字符数组。
2.1.5 表示代码
2.1.6 布尔代数简介
2.1.7 C语言中的位级运算
- 位级运算的一个常见用法就是实现掩码运算
- 例子:位级运算
x&0xFF生成一个由x的最低有效字节组成的值。
- 例子:位级运算
2.1.8 C语言中的逻辑运算
- 逻辑运算符&&和||与它们对应的位级运算&和|之间第二个重要的区别是,如果对第一个参数求值就能确定表达式的结果,那么逻辑运算符就不会对第二个参数求值就能确定表达式的结果,那么逻辑运算符就不会对第二个参数求值。因此,例如,表达式
a&&5/a将不会造成被零除,而表达式p&&*p++也不会导致间接引用空指针。
2.1.9 C语言中的移位运算
- 移位运算是从左至右可结合的。
- 机器支持两种形式的右移:逻辑右移和算术右移。逻辑右移在左端补k个0,算术右移在左端补k个最高有效位的值。
- 实际上,几乎所有的编译器/机器组合都对有符号数使用算术右移。
- 另一方面,对于无符号数,右移必须是逻辑的。
若大于位
位移量通过计算mod得到。
- 加法和减法的优先级比移位运算要高。
2.2 整数表示
B:二进制;
T:补码;
U:无符号。
整数的数据与算术操作术语,下标表示数据表示中的位数

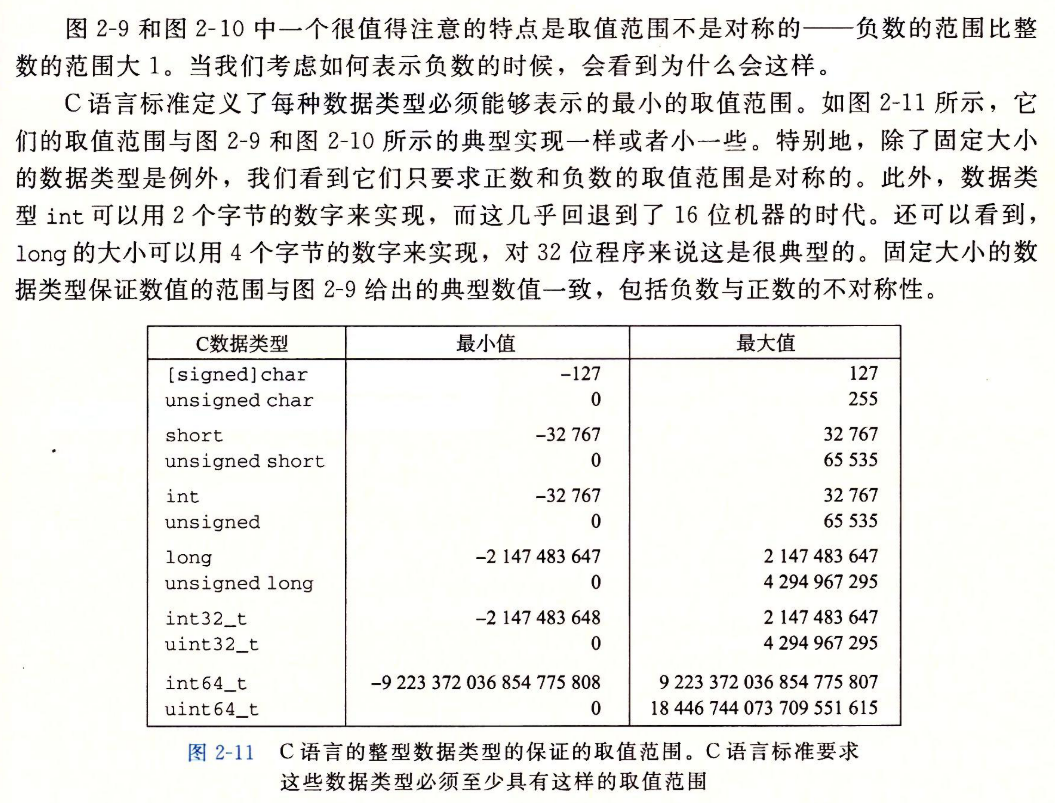
2.2.1 整型数据类型
C语言整型数据类型的典型取值范围


2.2 无符号数的编码
无符号数编码的定义
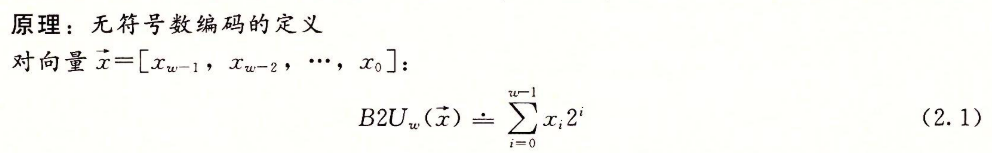
- 函数能够被定义为一个映射:。
无符号数编码的唯一性

2.2.3 补码编码
补码编码的定义

补码编码的唯一性

-
补码的范围是不对称的:。
-
最大的无符号数值刚好比补码的最大值的两倍的大一点:。
注意和由同样的位表示——一个全1的串。
2.2.4 有符号数与无符号数之间的转换
- 假设变量x声明位int,u声明为unsigned,表达式(unsigned)x会将x的值转换成一个无符号数值,而(int)u将u的值转换成一个有符号整数。
补码转换为无符号数:
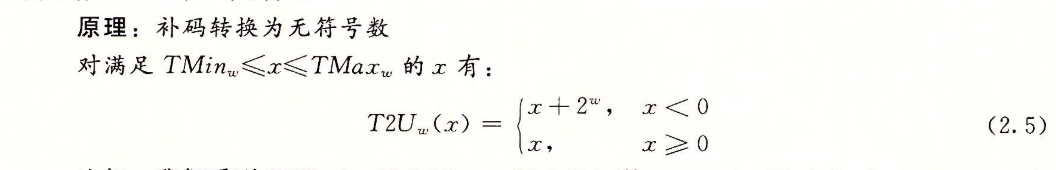
无符号数转化为补码
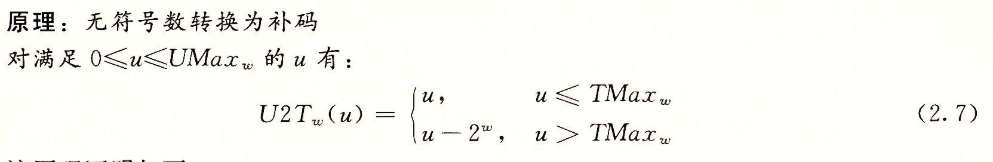
2.2.5 C语言中的有符号数与无符号数
- 如果它的一个运算数是有符号而另一个是无符号的,那么C语言会隐式地将有符号参数强制类型转换为无符号数。
2.2.6 扩展一个数字的位表示
零扩展
-
要将一个无符号数转换为一个更大的数据类型,我们只要简单的在表示的开头添加0。这种运算被称为零扩展(zero extension)

符号扩展
-
要将一个补码数字转换为一个更大的数据类型,可以执行一个符号扩展(sign extension)
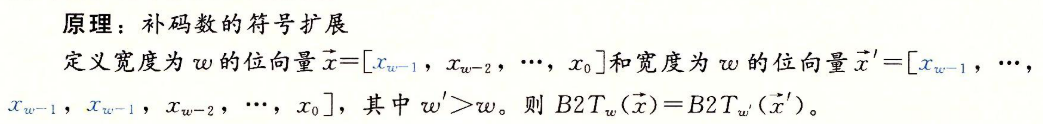
2.2.7 截断数字
截断无符号数

截断补码数值

2.2.8 关于有符号数与无符号数的建议
2.3 整数运算
2.3.1 无符号加法
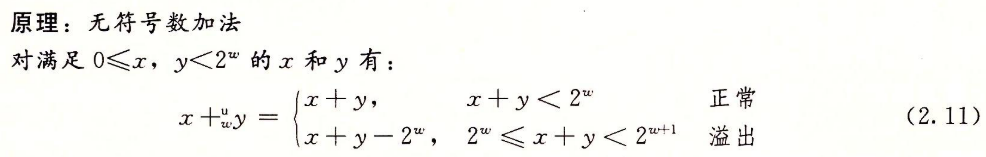
检测无符号数中加法的溢出

无符号数求反

2.3.2 补码加法

检测补码加法中的溢出

2.3.3 补码的非

2.3.4 无符号乘法

2.3.5 补码乘法

无符号和补码乘法的位级等价性

2.3.6 乘以常数
-
编译器使用了一项重要的优化,试着用移位和加法运算的组合来代替乘以常数因子的乘法。


2.3.7 除以2的幂
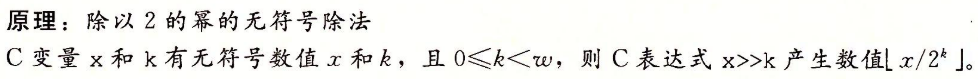

-
我们可以通过在移位前”偏置(biasing)”这个值,来修正这种不合适的舍入。

-
同乘法不同,我们不能用除以2的幂的除法来表示除以任何常数K的除法。
2.3.8 关于整数运算的最后思考
2.4 浮点数
2.4.1 二进制小数
2.4.2 IEEE浮点表示
-
IEEE浮点标准用的形式来表示一个数:

标准浮点格式

单精度浮点数值的分类

情况1:规格化的值
-
阶码的值,其中是无符号数,其位表示为,而是一个等于(单精度是127,双精度是1023)的偏置值。由此产生指数的取值范围,对于单精度是~,而对于双精度是~,
-
小数字段frac被解释为描述小数值,其中,其二进制表示为0,,也就是二进制小数点在最高有效位的左边。尾数定义为。有时,这种方式也叫做隐含的以1开头的(implied leading 1)表示。
情况2:非规格化的值
-
阶码值是,而尾数的值是,也就是小数字段的值,不包含隐含的开头的1
-
符号位是0,阶码字段全为0(表明是一个非规格化值),而小数域也全为0,这就得到。令人奇怪的是,当符号位为1,而其他域全为0时,我们得到值。
情况3:特殊值
- 最后一类数值时当指阶码全为1的时候出现的。当小数域全为0时,得到的值表示无穷,当时是,或者当时是。当我们把两个非常大的数相乘,或者除以零时,无穷能够表示溢出的结果。当小数域为非零时,结果值被称为“NaN”,即“不是一个数(Not a Number)”的缩写。
2.4.3 数字示例

2.4.4 舍入
- 向偶数舍入在大多数现实情况中避免了这种统计误差。在50%的时间里,它将向上舍入,而在50%的时间里,它将向下舍入。
- 在我们不想舍入到整数时,也可以使用向偶数舍入。我们只是简单地考虑最低有效数字是奇数还是偶数。
- 相似地,向偶数舍入法能够运用在二进制小数上,我们将最低有效位的值0认为是偶数,值1认为是奇数。
2.4.5 浮点运算
浮点加法
- 浮点加法不具有结合性,这是缺少的最重要的群属性。
- 另一方面,浮点加法满足了单调性属性。
浮点乘法
- 它是可交换的。
- 它不具有可结合性。
- 在加法上不具备分配性。
2.4.6 C语言中的浮点数
2.5 小结
第3章 程序的机器级表示
- 计算机执行机器代码,用字节序列编码低级的操作。
3.1 历史观点
3.2 程序编码
- 假设一个C程序,有两个文件p1.c和p2.c。我们用Unix命令行编译这些代码:
1 | |
- 命令gcc指的就是GCC C编译器。因为这是Linux上默认的编译器,我们也可以简单地用cc来启动它。编译选项-Og告诉编译器使用会生成符合C代码整体结构的机器代码优化等级。使用较高级别优化产生的代码会严重变形,以至于产生的机器代码和初始源代码之间的关系非常难以理解。
3.2.1 机器级代码
-
汇编代码表示非常接近于机器代码。与机器代码的二进制格式相比,汇编代码的主要特点是它用可读性更好的文本格式表示。
x86-64的机器代码与原始C代码的差别非常大。一些通常对C语言程序员隐藏的处理器状态都是可见的:
- 程序计数器(通常称为“PC”,在x86-64中用%rip表示)给出将要执行的下一条指令在内存中的地址。
- 整数寄存器文件包含16个命名的位置,分别存储64位的值。这些寄存器可以存储地址(对应于C语言的指针)或整数数据。有的寄存器被用来记录某些重要的程序状态,而其他的寄存器用来保存临时数据,例如过程的参数和局部变量,以及函数的返回值。
- 条件码寄存器保存着最近执行的算术或逻辑指令的状态信息。它们用来实现控制或数据流中的条件变化,比如说用来实现if和while语句。
- 一组向量寄存器可以存放一个或多个整数或浮点数值。
3.2.2 代码示例
-
要查看机器代码文件的内容,有一类称为反汇编器(disassembler)的程序非常有用。这些程序根据机器代码产生一种类似于汇编代码的格式。在Linux系统中,带‘-d’命令行标志的程序OBJDUMP(表示"object dump")可以充当这个角色。
1
linux> objdump -d test.o -
其中一些关于机器代码和它的反汇编特性值得注意:

3.2.3 关于格式的注解
3.3 数据格式
- 由于是从16位体系结构扩展成32位的,Intel用术语“字(word)”表示16位数据类型。因此,称32位数为"双字(double word)",称64位数为“四字(quad word)”。
C语言数据类型在x86-64中的大小
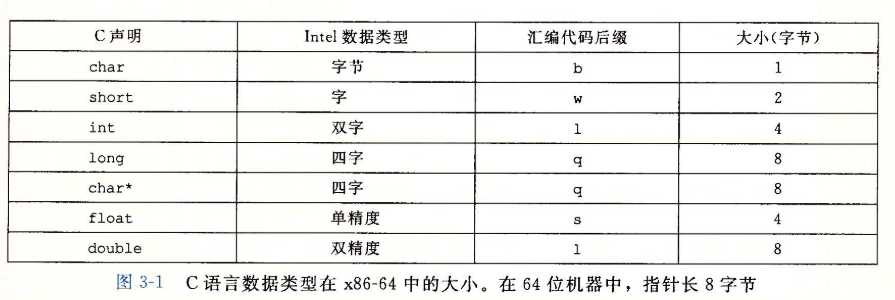
- 大多数GCC指令都有一个字符的后缀,表明操作数的大小。
3.4 访问信息
-
一个x86-64的中央处理单元(CPU)包含一组16个存储64位值的通用目的寄存器。这些寄存器用来存储整数数据和指针。

-
指令可以对这16个寄存器的低位字节中存放的不同大小的数据进行操作。
-
生成1字节和2字节的数字的指令会保持剩下的字节不变;生成4字节数字的指令会把高位4个字节置为0。
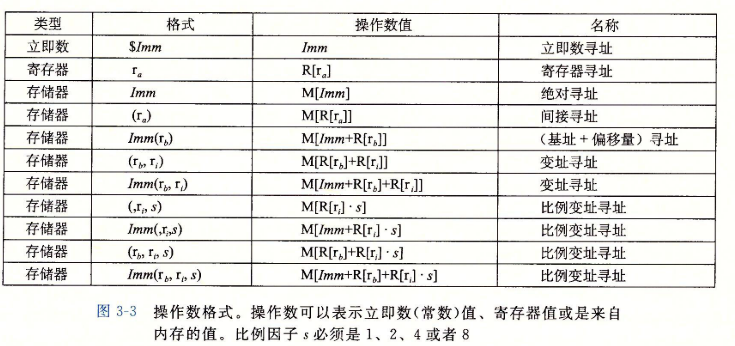
3.4.1 操作数指示符
- 大多数指令有一个或多个操作数(operand),指示出执行一个操作中要使用的源数据值,以及放置结果的目的位置。
- 各种不同的操作数的可能性被分为三种类型:
- 立即数(immediate),立即数的书写方式是’$‘后面跟一个用标准C表示法表示的整数。
- 寄存器(register)。我们用符号表示任意寄存器,用引用来表示它的值,这是将寄存器集合看出一个数字R,用寄存器表示符作为索引。
- 内存引用。。
操作数格式
3.4.2 数据传送指令
最简单形式的数据传送指令——MOV类
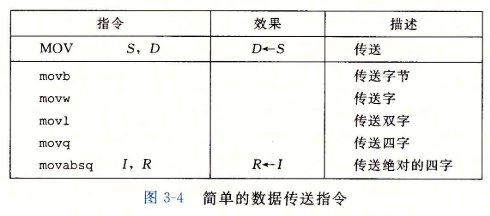
- 源操作数指定的值是一个立即数,存储在寄存器中或内存中。目的操作数指定一个位置,要么是一个寄存器或者是一个内存地址。
- x86-64加了一条限制,传送指令的两个操作数不能都指向内存位置。寄存器部分的大小必须与指令最后一个字符(’b‘,’w‘,’l‘或’q‘)指定的大小匹配。
- 任何为寄存器生成32位值的指令都会把该寄存器的高位部分置成0.
零扩展和符号扩展数据传送指令
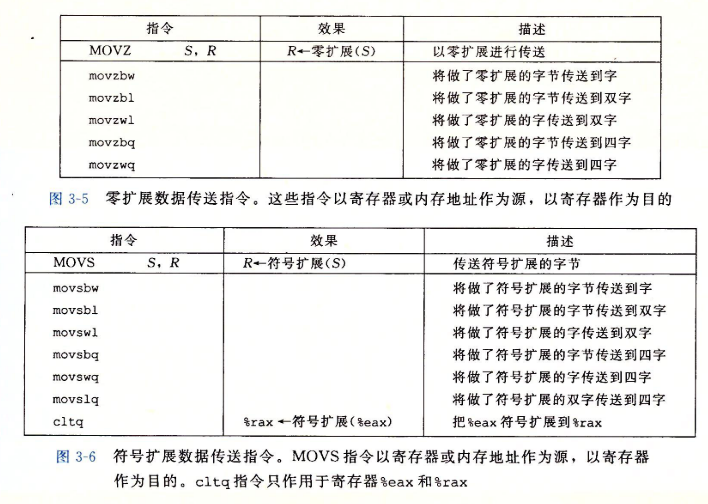
3.4.3 数据传送示例
- 我们看到C语言中所谓的“指针”其实就是地址。间接引用指针就是将该指针放在一个寄存器中,然后在内存引用中使用这个寄存器。其次,像x这样的局部变量通常是保存在寄存器中,而不是内存中。
- 访问寄存器比访问内存快得多。
3.4.4 压入和弹出栈数据
-
栈可以实现位一个数组,总是从数组的一段插入和删除元素。这一端被称为栈顶。
-
栈向下增长。

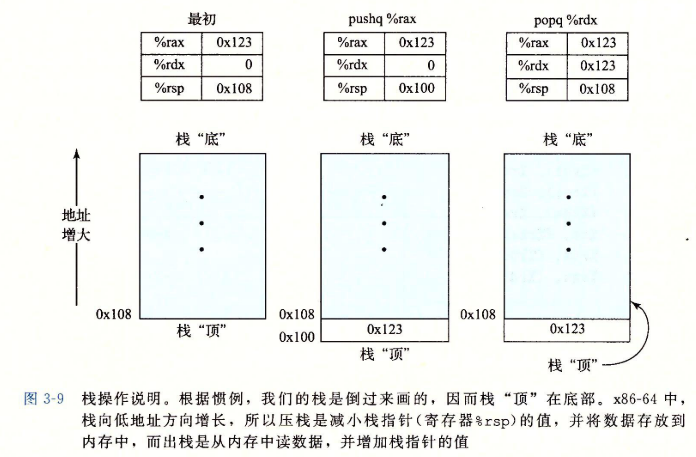
- 无论如何,%rsp指向的地址总是栈顶。
3.5 算术和逻辑操作
整数算术操作
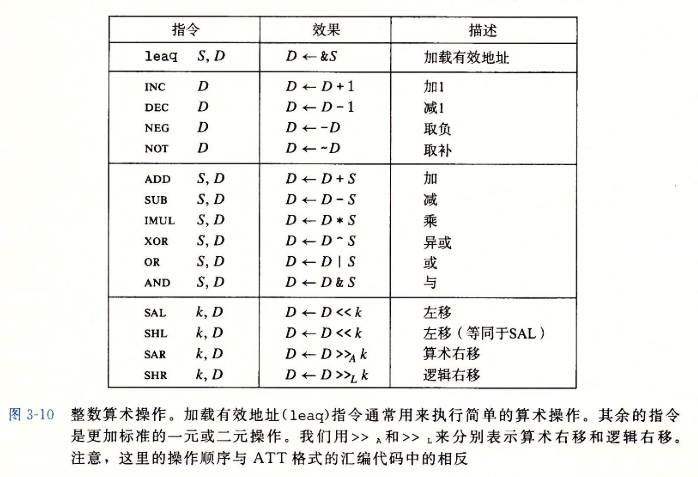
3.5.1 加载有效地址
- 加载有效地址(load吗effective address)指令leaq实际上是movq指令的变形。
- 我们用C语言的地址操作符&S说明这种计算。
- 它还可以简洁地描述普通的算术操作。例如如果寄存器%rdx的值为x,那么指令leaq 7(%rdx,%rdx,4),%rax将设置寄存器%rax的值为5x+7。
3.5.2 一元和二元操作
- 一元操作只有一个操作数,即是源又是目的。这个操作数可以是一个寄存器,也可以是一个内存位置。
- 二元操作的第一个操作数可以是立即数,寄存器或是内存地址。第二个操作数可以是寄存器或是内存位置。
3.5.3 移位操作
- 移位量可以是一个立即数,或是放在单字节寄存器%cl中。(这些指令很特别,因为只允许以这个特定发的寄存器作为操作数。)
- x86-64中,移位操作对位长的数据值进行操作,移位量由%cl寄存器的低决定的,这里。高位会被忽略。
- 移位操作的目的操作数可以是一个寄存器或是一个内存位置。
3.5.4 讨论
3.5.5 特殊的算术操作

- 这两条指令都要求一个参数必须在寄存器%rax中,而另一个作为指令的源操作数给出。然后乘积存放在寄存器%rdx(高64位)和%rax(低64位)中。
- 有符号出发指令idivl将寄存器%rdx(高64位)和%rax(低64位)中的128位数作为被除数,而除数作为指令的操作数给出。指令将商存储在寄存器%rax中,将余数存储在寄存器%rdx中。
3.6 控制
- 机器代码提供两种基本的低级机制来实现有条件的行为:测试数据值,然后根据测试的结果来改变控制流或者数据流。
3.6.1 条件码
-
除了整数寄存器,CPU还维护着一组单个位的条件码(condition code)寄存器。
-
最常用的条件码有:

-
leaq指令不改变任何条件码,因为它是用来进行地址计算的。除此之外,图3-10中列出的所有指令都会设置条件码。
-
对于逻辑操作,例如XOR,进位标志和溢出标志会设置为0。
-
对于移位操作,进位标志将设置为最后一个被移出的位,而溢出标志设置为0。
-
INC和DEC指令会设置溢出和零标志,但是不会改变进位标志。
-
还有两类指令(有8、16、32和64位形式),它们只设置条件码而不改变任何其他寄存器;如图3-13所示。
-
CMP指令根据两个操作数的差来设置条件码。除了只设置条件码而不更新目的寄存器之外,CMP指令与SUB指令的行为是一样的。
-
TEST指令的行为和AND指令一样,除了它们只设置条件码而不改变目的寄存器的值。典型的用法是,两个操作数是一样的(例如,testq %rax,%rax用来检查%rax是负数、零还是正数),或其中的一个操作数是一个掩码,用来指示哪些位应该被测试。
3.6.2 访问条件码
-
条件码通常不会直接读取,常用的使用方法有三种:
- 1)可以根据条件码的某种组合,将一个字节设置为0或者1
- 2)可以条件跳转到程序的某个其他部分
- 3)可以有条件地传送数据
-
对于第一种情况,我们将这一整类指令称为SET指令
-
一条SET指令的目的操作数是低位字节寄存器元素(图3-2)之一,或是一个字节的内存位置,指令会将这个字节设置成0或者1。
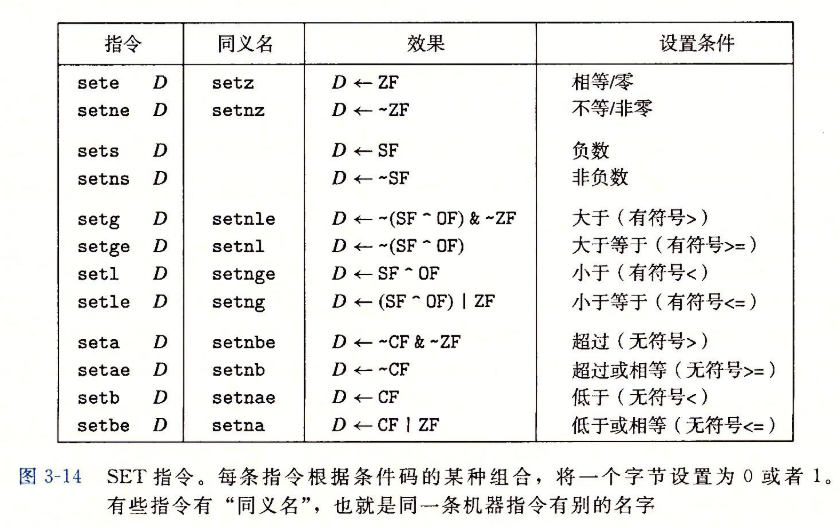

-
注意cmpq指令的比较顺序(第2行)。虽然参数列出的顺序先是%rsi(b)再是%rdi(a),实际上比较的是a和b。还要记得,正如在3.4.2节种讨论过的那样,movzbl指令不仅会把%eax的高3个字节清零,还会把整个寄存器%rax的高4个字节都清零。
-
图3-15列举了不同的跳转指令。jmp指令是无条件跳转,它可以是直接跳转,即跳转目标作为指令的一部分编码;也可以是间接跳转,即跳转目标是从寄存器或内存位置中读出的。
3.6.5 用条件控制来实现条件分支
- 将条件表达式和语句从C语言翻译成机器代码,最常用的方式是结合有条件和无条件跳转。
3.6.6 用条件传送来实现条件分支
-
实现条件操作的传统方法是通过使用控制的条件转移。当条件满足时,程序沿着一条执行路径执行,而当条件不满足时,就走另一条路径。这种机制简单而通用,但是在现代处理器上,它可能会非常低效。
-
一种替代策略是使用数据的条件转移。这种方法计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个。

-
处理器通过使用流水线(pipelining)来获取高性能。
-
当机器遇到条件跳转(也称为“分支”)时,只有当分支条件求值完成之后,才能决定分支往哪边走。处理器采用非常精密的分支预测逻辑来猜测每条跳转指令是否会执行。只要它的猜测还比较可靠,指令流水线中就会充满着指令。另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后所有指令已做的工作,然后再开始用从正确位置处起始的指令去填充流水线。
-
汇编器可以从目标寄存器的名字推断出条件传送指令的操作数长度,所以对所有的操作数长度,都可以使用同一个的指令名字。
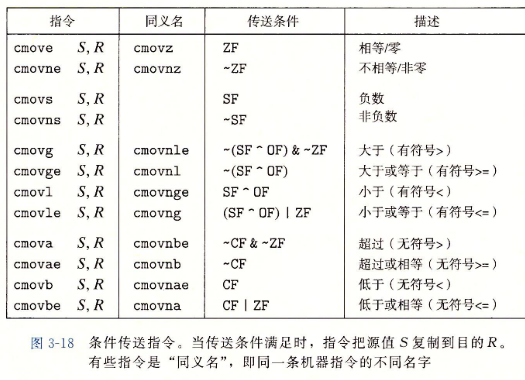
- 同条件跳转不同,处理器无需预测测试的结果就可以执行条件传送。
-
编译器必须考虑浪费的计算和由于分支预测错误所造成的性能出发之间的相对性能。说实话,编译器并不具有足够的信息来做出可靠的决定。
- 对GCC的实验表明,只有当两个表达式都很容易计算时,例如表达式分别都只是一个加法指令,它才会使用条件传送。
- 即时许多分支预测错误的开销会超过更复杂的计算,GCC还是会使用条件控制转移。
3.6.7 循环
1.do-while循环
2.while循环
3.for循环
3.6.8 switch语句
- switch(开关)语句可以根据一个整数索引值进行多重分支(multiway branching)。
- 在处理具有多种可能结果的测试时,这种语句特别有用。它们不仅提高了C代码的可读性,而且通过跳转表(jump table)这种数据结果使得实现更加高效。
3.7 过程
- 过程P调用过程Q,Q执行后返回到P。这些动作包括下面一个或多个机制:
- 传递控制。在进入过程Q的时候,程序计数器必须被设置为Q的代码的起始地址,然后在返回时,要把程序计数器设置为P中调用Q后面那条指令的地址。
- 传递数据。P必须能够向Q提供一个或多个参数,Q必须能够向P返回一个值。
- 分配和释放内存。在开始时,Q可能需要为局部变量分配空间,而在返回前,又必须释放这些存储空间。
3.7.1 运行时栈
-
当P调用Q时,控制和数据信息添加到栈尾。当P返回时,这些信息会被释放掉。
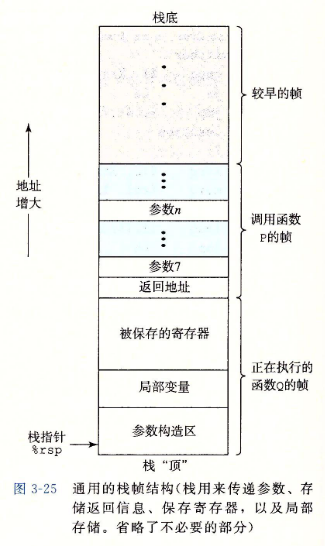
-
通过寄存器,过程P可以传递最多6个整数值(也就是指针和整数),但是如果Q需要更多的参数,P可以在调用Q之前在栈帧里存储好这些参数。
3.7.2 转移控制
-
这个信息是用指令call Q调用过程Q来记录的。该指令会把地址A压入栈中,并将PC设置为Q的起始地址。压入的地址A称为返回地址,是紧跟在call指令后面的那条指令的地址。对应的指令ret会从栈中弹出地址A,并将PC设置为A。

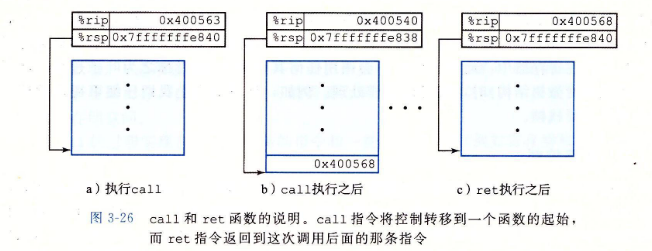
3.7.3 数据传送
- 通过栈传递参数时,所有的数据大小都向8的倍数对齐。
- 过程Q可以通过寄存器访问参数,有必要的话可以通过栈访问。相应地,如果Q也调用了某个有超过6个参数的函数,它也需要在自己的栈帧中为超过6个的部分参数分配空间。
3.7.4栈上的局部存储
3.7.5 寄存器中的局部存储空间
- 根据惯例,寄存器%rbx、%rbp和%r12~%r15被划分为被调用者保存寄存器。当过程P调用过程Q时,Q必须保存这些寄存器的值,保证它们的值在Q返回到P时与Q被调用时是一样的。过程Q保存一个寄存器的值不变,要么就是根本不去改变它,要么就是把原始值压入栈中,改变寄存器的值,然后在返回前从栈中弹出旧值。
- 所有其他的寄存器,除了栈指针%rsp,都分类为调用者保存寄存器。这就意味着任何函数都能修改它们。
3.7.6 递归过程
3.8数组的分配和访问
3.8.1 基本原则
- 对于数据类型T和整型常数N,声明如下:
1 | |
起始位置表示为。这个声明有两个效果。首先,它在内存中分配一个字节的连续区域,这里是数据类型T的大小(单位为字节)。
其次,它引入了标识符A,可以用A来作为指向数组开头的指针,这个指针的值就是。可以用0~N-1的整数索引来访问该数组元素。数组元素会被存放在地址为的地方。
3.8.2 指针运算
-
C语言允许对指针进行运算,而计算出来的值会根据该指针引用的数据类型的大小进行伸缩。也就是说,如果是一个指向类型为的数据的指针,的值为,那么表达式的值为,这里是数据类型的大小。
-
单操作数操作符’&'和‘*’可以产生指针和间接引用指针。也就是,对于一个表示某个对象的表达式Expr,&Expr是给出该对象地址的一个指针。对于一个表示地址的表达式AExpr,*AExpr给出该地址处的值。因此,表达式Expr与*&Expr是等价的。可以对数组和指针应用数组下标的操作。数组引用A[i]等同于表达式*(A+i)。

3.8.3 嵌套的数组
-
当我们创建数组的数组时,数组分配和引用的一般原则也是成立的。例如,声明
1
int A[5][3];
等价于下面的声明
1 | |
- 通常来说,对于一个声明如下的数组:
1 | |
它的数组元素的内存地址为
D[i][j]=
3.8.4 定长数组
3.8.5 变长数组
3.9 异质的数据结构
- C语言提供了两种将不同类型的对象组合到一起创建数据类型的机制:结构(structure),用关键字struct来声明,将多个对象集合到一个单位中;联合(union),用关键字union来声明,允许使用几种不同的类型来引用一个对象。
3.9.1 结构
- 类似于数组的实现,结构的所有组成部分都存放在内存中一段连续的区域内,而指向结构的指针就是结构第一个字节的地址。
3.9.2 联合
- 联合声明的语法与结构的语法一样,只不过语义相差比较大。它们是用不同的字段来引用相同的内存块。

-
对于类型union U3 * 的指针p,p->c、p->i[0]和p->v引用的都是数据结构的起始位置。还可以观察到,一个联合的总的大小等于它最大字段的大小。

-
在这段代码中,我们以一个数据类型来存储联合中的参数,又以另一种数据类型来访问它。结果会是u具有和d一样的位表示,包括符号位字段、指数和尾数。
3.9.3 数据对齐
-
许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某种类型对象的地址必须是某个值K(通常是2、4或8)的倍数。这种对齐限制简化了形成处理器和内存系统之间的硬件设计。


3.10 在机器级程序中将控制和数据结合起来
3.10.1 理解指针
- 每个指针都对应一个类型。
- 每个指针都有一个值。这个值是某个指定类型的对象的地址。特殊的NULL(0)值表示该指针没有指向任何地方。
- 指针用‘&’运算创建。
- 操作符用于间接引用指针。其结果是一个值,它的类型与该指针的类型一致。
- 数组与指针紧密联系。一个数组的名字可以像一个指针变量一样引用(但是不可以修改)。数组引用(例如a[3])与指针运算和间接引用(例如*(a+3))有一样的效果。
- 将指针从一种类型转换成另一种类型,只改变它的类型,而不改变它的值。
- 如果p是一个char*类型的指针,它的值为p,那么表达式(int*)p+7计算为p+28,而(int*)(p+7)计算为p+7。(强制类型转换的优先级高于加法)
- 指针也可以指向函数。
- 函数指针的值是该函数机器代码表示中第一条指令的地址。
3.10.2 应用:使用GDB调试器
GDB命令示例

3.10.3 内存越界引用和缓冲区溢出
- C对于数组引用不进行任何边界检查,而且局部变量和状态信息都存放在栈中。
缓冲区溢出
- 一种特别常见的状态破坏称为缓冲区溢出(buffer overflow)。
- 我们的echo代码很简单,但是有点太随意了。更好一点的版本是使用fgets函数,它包括一个参数,限制待读入的最大字节数。
- 使用gets或其他任何能导致存储溢出的函数,都是不好的编程习惯。不幸的是,很多常用的库函数,包括strcpy、strcat和sprintf,都有一个属性——不需要告诉它们目标缓冲区的大小,就产生一个字节序列[97]。这样的情况就会导致缓冲区溢出。
- 通常,输入给程序一个字符串,这个字符串包含一些可执行代码的字节编码,称为攻击代码(exploit code)。
3.10.4 对抗缓冲区溢出攻击
1.栈随机化
- 栈随机化的思想使得栈的位置在程序每次运行时都有变化。因此,即使许多机器都运行同样的代码,它们的栈地址都是不同的。实现的方式是:程序开始时,在栈上分配一段0~n字节之间的随机大小的空间。
- 例如,使用分配函数alloca在栈上分配指定字节数量的空间。程序不使用这段空间,但是它会导致程序每次执行时后续的栈位置发生了变化。
- 分配的范围n必须足够大,才能获得足够多的栈地址变化,但是又要足够小,不至于浪费程序太多的空间。
一个执着的攻击者总是能够用蛮力克服随机化。
- 一种常见的把戏就是在实际的攻击代码前插入很长的一段nop(读作”no op“,no operation的缩写)指令。执行这种指令除了对程序计数器加一,使之指向下一条指令外,没有任何效果。只要攻击者能够猜中这段序列的某个地址,程序就会经过这个序列,到达攻击代码。这个序列常用的术语是”空操作雪橇(nop sled)“[97],意思是程序会”滑过“这个序列。
2.栈破坏检测

3. 限制可执行代码区域
-
最后一招是消除攻击者向系统中插入可执行代码的能力。一种方法是限制哪些内存区域能够存放可执行代码。在典型的程序中,只有保存编译器产生的代码的的那部分内存才需要是可执行的。其他部分可以被限制为只允许读和写。
-
变长数组意味着在编译时无法确定栈帧的大小。
为了管理变长栈帧,x86-64代码使用寄存器%rbp作为帧指针(frame pointer)(有时称为基指针(base pointer))。
然后在函数的整个执行过程中,都使得%rbp指向那个时刻栈的位置,然后用固定长度的局部变量(例如i)相对于%rbp的偏移量来引用它们。
3.11 浮点代码
-
如图3-45所示,AVX浮点体系结构允许数据存储在16个YMM寄存器中,它们的名字为%ymm0~%ymm15。每个YMM寄存器都是256位(32字节)。当对标量数据操作时,这些寄存器只保存浮点数,而且只使用低32位(对于float)或64位(对于double)。汇编代码用寄存器SSE XMM寄存器名字%xmm0~%xmm15来引用它们,每个XMM寄存器都对应的YMM寄存器的低128位(16字节)。

3.11.1 浮点传送和转换操作
浮点传送指令
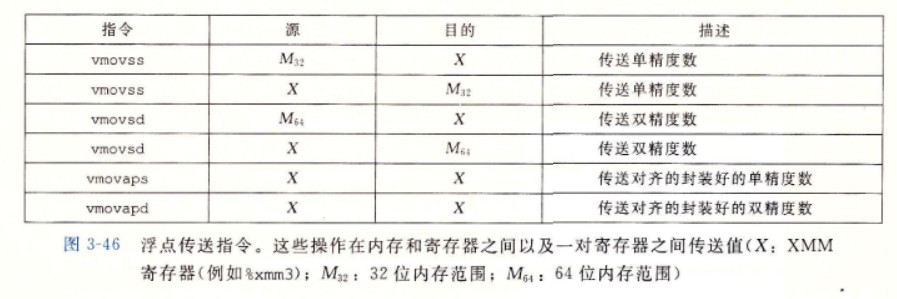
双操作浮点转换指令

三操作数浮点转换指令
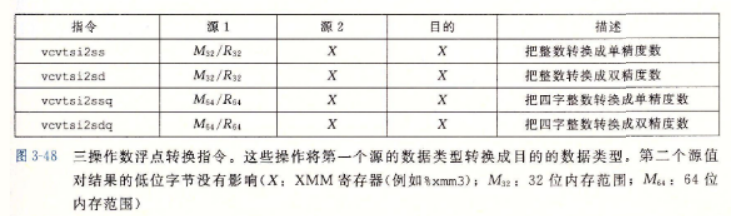
3.11.2 过程中的浮点代码
- XMM寄存器用来向函数传递浮点参数,可以看到如下规则:
- XMM寄存器%xmm0~%xmm7最多可以传递8个浮点参数。按照参数列出的顺序使用这些寄存器,可以通过栈传递额外的浮点参数。
- 函数使用寄存器%xmm0来传递浮点值。
- 所有的XMM寄存器都是调用者保存的。被调用者可以不用保存就覆盖这些寄存器中任意一个。
3.11.3 浮点运算操作
-
每条指令有一个()或两个()源操作数,和一个目的操作数。第一个源操作数可以是一个XMM寄存器或一个内存位置。第二个源操作数和目的操作数都必须是XMM寄存器。

3.11.4 定义和使用浮点常数
- 和整数运算操作不同,AVX浮点操作不能以立即数值作为操作数。相反,编译器必须为所有的常量值分配和初始化存储空间。
3.11.5 在浮点代码中使用位级操作

3.11.6 浮点比较操作

-
它们遵循以相反顺序列出操作数的ATT格式惯例。参数必须在XMM寄存器中,而可以在XMM寄存器中,也可以在内存中。
-
浮点比较指令设置三个条件码:零标志位ZF、进位标志位CF和奇偶标志位PF。
-
对于整数操作,当最近的一次算术或逻辑运算产生的值的最低位字节是偶校验的(即这个字节中有偶数个1),那么就会设置这个标志位。不过对于浮点比较,当两个操作数中任一个是NaN时,会设置该位。
-
条件码的设置条件如下:
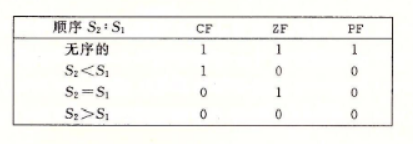
当任一操作数为NaN时,就会出现无序的情况。可以通过奇偶标志位发现这种情况。通常jp(jump on parity)指令时条件跳转,条件就是浮点比较得到一个无序的结果。
3.11.7 对浮点代码的观察结论
3.12 小结
第4章 处理器体系结构
跳过
第5章 优化程序性能
- 编写高效程序需要做到以下几点:
- 第一,我们必须选择一组适当的算法和数据结构。
- 第二,我们必须编写出编译器能够有效优化以转换成高效可执行代码的源代码
- 然而,即使时最好的编译器也会受到妨碍优化的因素(optimization blocker)的阻碍,妨碍优化的因素就是程序行为中那些严重依赖于执行环境的方面。
- 程序优化的第一步就是消除不必要的工作,让代码尽可能有效的执行所期望的任务。
- 了解了处理器的运作,我们就可以进行程序优化的第二步,利用处理器提供的指令级并行(instruction-level parallelism)能力,同时执行多条指令。
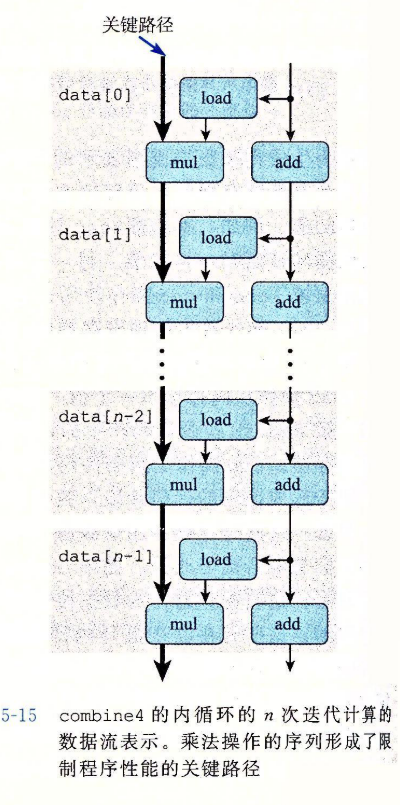
- 正如我们会看到,常常通过确认关键路径(critical path)来决定执行一个循环所需要的时间(或者说,至少是一个时间下界)。所谓关键路径是在循环的反复执行过程中的数据相关链。
5.1 优化编译器的能力和局限性
- 最简单的控制是指定优化级别。
- 编译器必须很小心地对程序只使用安全的优化,也就是说对于程序可能遇到的所有可能的情况,在C语言标准提供的保证之下,优化后得到的程序和未优化的版本有一样的行为。
- 两个指针可能指向同一个内存位置的情况称为内存别名使用(memory aliasing)。在只执行安全的优化中,编译器必须假设不同的指针可能会指向内存中的同一个位置。
- 这造成了一个主要的妨碍优化的因素。
- 第二个妨碍优化的因素是函数调用。
- 包含函数调用的代码可以用一个称为内联函数替换(inline substitution,或者简称”内联(inlining)“)的过程进行优化,此时将函数调用替换为函数体。
5.2 表示程序的性能
-
我们引入度量标准每元素的周期数(Cycles Per Element,CPE),作为一种表示程序性能并指导我们改进代码的方法。
-
函数psum1每次迭代计算结果向量的一个元素。第二个函数使用循环展开(loop unrolling)的技术,每次迭代计算两个元素。
5.3 程序示例
5.4 消除循环的低效率

- 这个优化是一类常见的优化的一个例子,称为代码移动(code motion)。这类优化包括识别要多次执行(例如在循环里)但是计算结果不会改变的计算。因而可以将计算移动到代码前面不会被多次求值的部分。
5.5 减少过程的调用
5.6 消除不必要的内存引用

-
按照图5-10中combine4所示的方式重写代码。引入一个临时变量acc,它在循环中用来累积计算出来的值。只有在循环完成之后结果才存放在dest中。正如下面的汇编代码所示,编译器现在可以用寄存器%xmm0来保存累计值。与combine3中的循环相比,我们将每次迭代的内存操作从两次读和一次写减少到只需要一次读。

5.7 理解现代处理器
- 当一系列操作必须按照严格顺序执行时,就会遇到延迟界限(latency bound),因为在下一条指令开始之前,这条指令必须结束。当代码中的数据相关限制了处理器利用指令级并行的能力时,延迟界限能够限制程序性能。
- 吞吐量界限(throughput bound)刻画了处理器功能单元的原始计算能力。这个界限是程序性能的终极限制。
5.7.1 整体操作
-
整个设计有两个主要部分:指令控制单元( Instruction Control Unit,ICU)和执行单元(Execution Unit,EU)。前者负责从内存中读出指令序列,并根据这些指令序列生成一组针对程序数据的基本操作;而后者执行这些操作。
-
ICU从指令高速缓存(instruction cache)中读取指令,指令高速缓存是一个特殊的高速存储器,它包含最近访问的指令。
-
现代处理器采用了一种称为分支预测(branch predication)的技术,处理器会猜测是否会选择分支,同时还预测分支的目标地址。使用投机执行(speculative execution)的技术,处理器会开始取出位于它预测的分支会跳到的地方的指令,并对指令译码,甚至在它确定分支预测是否正确之前就开始取出位于它预测的分支会跳到的地方的指令,并对指令译码,甚至在它确定分支预测是否正确之前就开始执行这些操作。如果过后确定分支预测错误,会将状态重新设置到分支点的状态,并开始取出和执行另一方向上的指令。标记为取值控制的块包括分支预测,以完成确定取哪些指令的任务。
-
EU接收来自取指单元的操作。
-
读写内存是由加载和存储单元实现的。

-
我们可以看出功能单元的这种组合具有同时执行多个同类型操作的潜力。它有4个功能单元可以执行整数操作,2个单元能执行加载操作,2个单元能执行浮点乘法。
-
在ICU中,退役单元(retirement unit)记录正在进行的处理,并确保它遵守机器级程序的顺序语义。
- 首先,一旦一条指令的操作完成了,而且所有引起这条指令的分支点也都被确认为预测正确,那么这条指令就可以退役(retire)了,所有对程序寄存器的更新都可以被实际执行了。另一方面,如果引起该指令的某个分支点预测错误,这条指令就会被清空(flushed),丢弃所有计算出来的结果。通过这种方法,预测错误就不会改变程序的状态了。
5.7.2 功能单元的性能
-
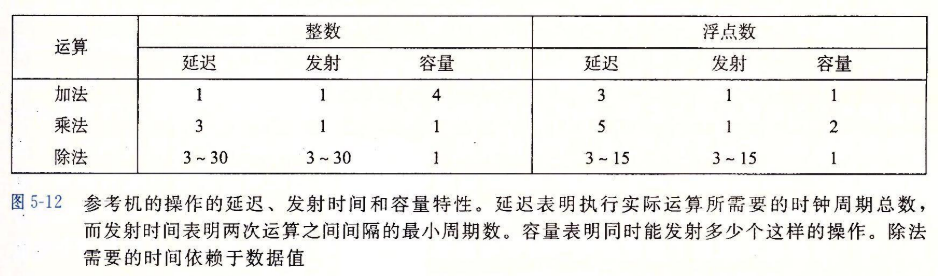
每个运算都是由以下数值来刻画的:
- 一个是延迟(latency),它表示完成运算所需要的总时间;
- 另一个是发射时间(issue time),它表示两个连续的同类型的运算之间需要的最小时钟周期数;
- 还有一个是容量(capacity),它表示能够执行该运算的功能单元的数量。
-
发射时间为1的功能单元被称为完全流水线化的(fully pipelined);每个时钟周期可以开始一个新的运算。出现容量大于1的运算是由于有多个功能单元。
-
除法器的发射时间等于它的延迟。
-
表达发射时间的一种更常见的方法是指明这个功能单元的最大吞吐量,定义为发射时间的倒数。一个完全流水线化的功能单元有最大的吞吐量,每个时钟周期一个运算。
- 对一个容量为C,发射时间为I的操作来说,处理器可能获得的吞吐量为每时钟周期C/I个操作。
-
我们用CPE值的两个基本界限来描述这种影响:
- 延迟界限给出了任何必须按照严格顺序完成合并运算的函数所需要的最小CPE值。
- 吞吐量界限给出了CPE的最小界限。
-
另一方面,四个功能单元都可以执行整数加法,处理器就有可能持续每个周期执行4个操作的速率。不幸的是,因为需要从内存读数据,这造成了另一个吞吐量界限。两个加载单元限制了处理器每个时钟周期最多只能读取两个数据值。
5.7.3 处理器操作的抽象类型
- 我们会使用程序的数据流(data-flow)表示,这是一种图形化的表示方法,展现了不同操作之间的数据相关时如何限制它们的执行顺序的。这些限制形成了图中的关键路径(critical path),这是执行一组机器指令所需时钟周期数的一个下界。
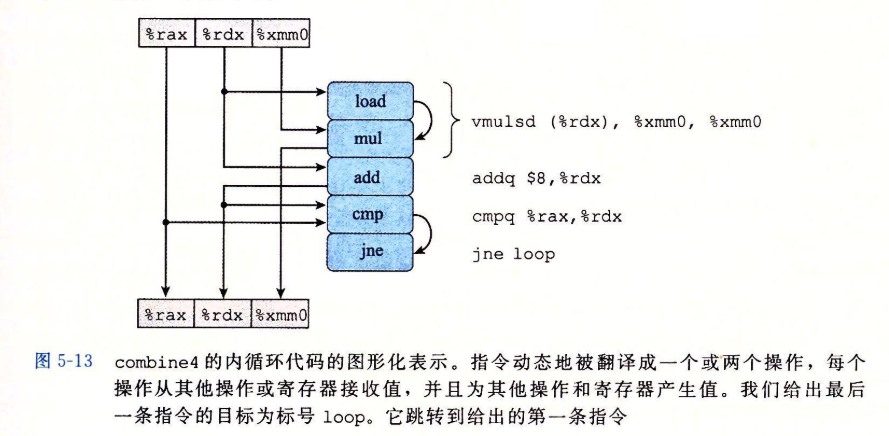
1.从机器级代码到数据流图
-
对于形成循环的代码片段,我们可以将访问到的寄存器分为四类:

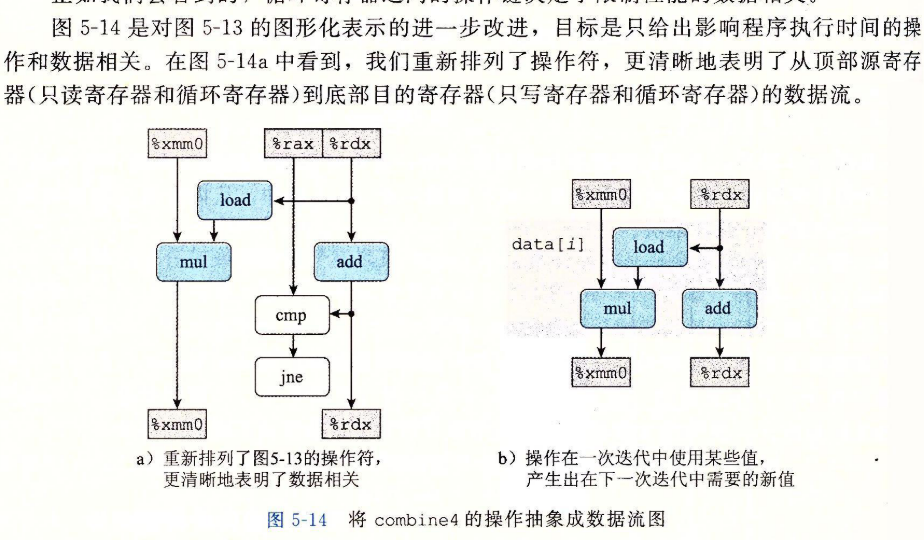
-
在图5-14b中,表明的是由于循环的一次迭代在循环寄存器中形成的数据相关。
其他性能因素
- 数据流表示中的关键路径提供的只是程序需要周期数的下界。还有其他一些因素会限制性能。
5.8 循环展开
- 循环展开是一种程序变换,通过增加每次迭代计算的元素的数量,减少循环的迭代次数。
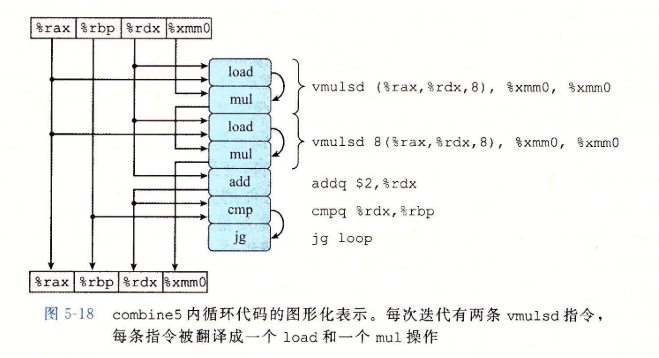
- 每条vmulsd指令被翻译成两个操作:一个操作是从内存中加载一个数组元素,另一个是把这个值乘以已有的累积值。
5.9 提高并行性
- 执行加法和乘法的功能单元是完全流水线化的,这意味着它们可以每个时钟周期开始一个新操作,并且有些操作可以被多个功能单元执行。
5.9.1 多个累积变量
- 对于一个可结合和可交换的合并运算来说,比如说整数加法或乘法,我们可以通过将一组合并运算分割成两个或更多的部分,并在最后合并结果来提高性能。

-
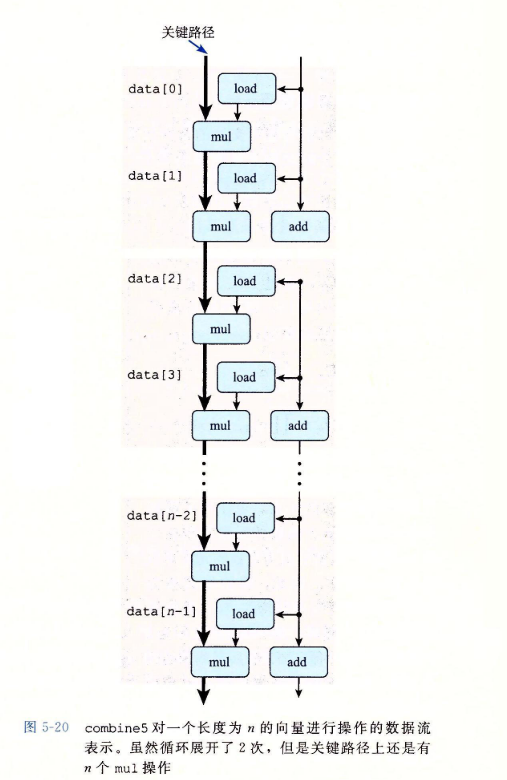
可以看到,现在有两条关键路径,一条对应于计算索引为偶数的元素的乘积(程序值acc0),另一条对应于计算索引为奇数的元素的乘积(程序值acc1)。
- 每条关键路径只包含n/2个操作。
- 对于不同的数据类型和合并运算的组合,延迟为L的操作的CPE等于L/2。
-
对于大多数应用程序来说,使性能翻倍要比冒对奇怪的数据模式产生不同的结果的风险更重要。
5.9.2 重新结合变换
-
在combnie5中,合并是以下面这条语句来实现的
1
acc = (acc OP data[i]) OP data[i+1]; -
而在combine7中,合并是以这条语句来实现的
1
acc = acc OP (data[i] OP data[i+1]); -
差别仅在于两个括号是如何放置的,我们称之为重新结合变换(rreassociation transformation),因为括号改变了向量元素与累计值acc的合并顺序,产生了我们称为“2x1a”的循环展开形式。
-
每次迭代内的第一个乘法都不需要等待前一次迭代的累计值就可以执行。因此,最小可能的CPE减小了2倍。
-
总的来说,重新结合变换能够减少计算中关键路径上操作的数量,通过更好地利用功能单元的流水线能力得到更好的性能。
-
大多数编译器不会尝试对浮点运算重新结合,因为这些运算不保证是可结合的。
5.10 优化合并代码的结果小结
5.11 一些限制因素
- 关键路径指明了执行该程序所需时间的一个基本的下界。也就是说,如果程序中有某条数据相关链,这条链上的所有延迟之和等于T,那么这个程序至少需要T个周期才能执行完。
- 我们还看到功能单元的吞吐量界限也是程序执行时间的一个下界。也就是说,假设一个程序一共需要N个某种运算的计算,而微处理器只有C个能执行这个操作的功能单元,并且这些单元的发射时间为I。那么这个程序的执行至少需要N*I/C个周期。
5.11.1 寄存器溢出
- 如果我们的并行度p超过了可用的寄存器数量,那么编译器会溢出(spilling),将某些临时值存放到内存中,通常是在运行时堆栈上分配空间。
5.11.2 分支预测和预测错误处罚
不要过分关心可预测的分支
5.12 理解内存性能
5.12.1 加载的性能
- 对两个加载单元而言,其每个时钟周期只能启动一条加载操作,所以CPE不可能小于0.50,对于每个被计算的元素必须加载k个值的应用,我们不可能获得低于k/2的CPE。
5.12.2 存储的性能
-
与加载操作一样,在大多数情况中,存储操作能够在完全流水化的模式中工作,每个周期开始一条新的存储。
-
与到目前为止我们已经考虑过的其他操作不同,存储操作并不影响任何寄存器的值。因此,就其本性来说,一系列存储操作不会产生数据相关。只有加载操作会受存储操作结果的影响,因为只有加载操作能从由存储操作写的那个位置读回值。
- 在图5-33的示例A中,参数src是一个指向数组元素a[0]的指针,而dest是一个指向数组元素a[1]的指针。从src读出的结果不受对dest的写的影响。在较大次数的迭代上测试这个示例得到CPE等于1.3。
- 在图5-33的示例B中,参数src和dest都是指向数组元素a[0]的指针。在这种情况中,指针引用*src的每次加载都会得到指针引用*dest的前次执行存储的值。一个内存读的结果依赖于一个最近的内存写。我们的性能测试表明示例B的CPE为7.3。写/读相关导致处理速度下降约6个时钟周期。
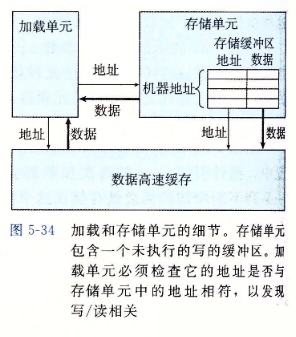
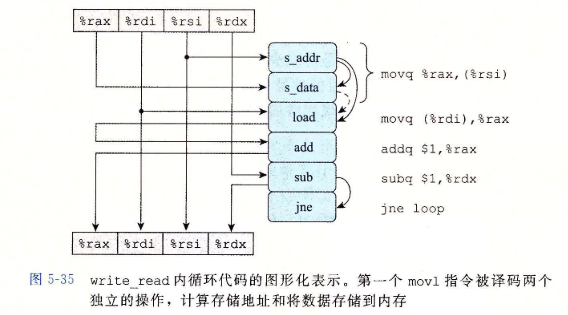
-
这张图中s_data和load操作之间由虚弧线。这个数据相关是有条件的:如果两个地址相同,load操作必须等待直到s_data将它的结果存放到存储缓冲区中,但是如果两个地址不同,两个操作就可以独立地进行。
5.13 应用:性能提高技术
-
- 高级设计。为遇到的问题选择适当的算法和数据结构。
-
- 基本编码原则。避免限制优化的元素,这样编译器就能产生高效的代码。
- 消除连续的函数调用。
- 消除不必要的内存引用。
-
- 低级优化。
- 展开循环
- 通过使用例如多个累积变量和重新结合等技术,找到方法提高指令级并行。
- 用功能性的风格重写条件操作,使得编译采用条件数据传送。
5.14 确认和消除性能瓶颈
5.14.1 程序剖析
5.14.2 使用剖析程序来指导优化
5.15 小结
第6章 存储器层次结构
- 存储器系统(memory system)是一个具有不同容量、成本和访问时间的存储设备的层次结构。CPU寄存器保持着最常用的数据。靠近CPU的小的、快速的高速缓存存储器(cache memory)作为一部分存储在相对慢速的主存储器(main memory)中数据和指令的缓冲区域。
- 计算机系统中一个基本而持久的思想:如果你理解了系统是如何将数据在存储器层次结构中上上下下移动的,那么你就可以编写自己的应用程序,使得它们的数据项存储在层次结构中较高的地方,在那里CPU能更快地访问到它们。
- 这个思想围绕着计算机程序的一个称为局部性(locality)的基本属性。
6.1 存储技术
6.1.1 随机访问存储器
-
随机访问存储器(Random-Access Memory,RAM)分为两类:静态的和动态的。**静态RAM(SRAM)比动态RAM(DRAM)**更快,但也贵很多。
-
静态RAM
-
动态RAM

-
传统的DRAM
DRAM芯片中的单元(位)被分成个超单元(supercell),每个超单元都由个DRAM单元组成,一个的DRAM总共存储了位信息。超单元被组织成一个行列的长方形阵列,这里。每个超单元有形如的地址,这里表示行,而表示列。
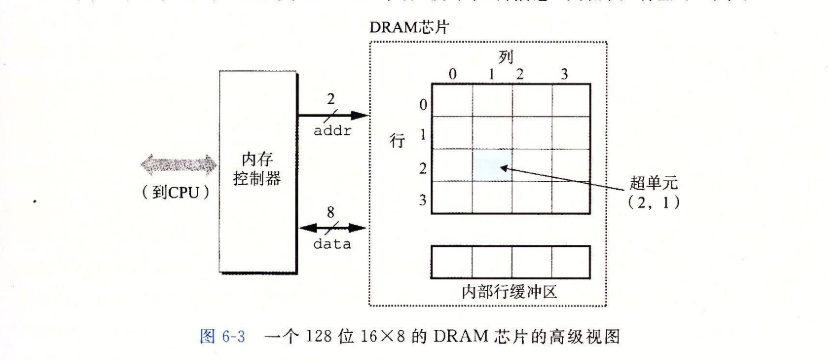
每个DRAM芯片被连接到某个称为内存控制器(memory controller)的电路,这个电路可以一次传送位到每个DRAM芯片或一次从每个DRAM芯片传出位。为了读出超单元()的内容,内存控制器将行地址发送到DRAM,然后是列地址。DRAM把超单元的内容发回给控制器作为响应。行地址称为RAS(Row Access Strobe,行访问选通脉冲)请求。列地址称为CAS(Column Access Strobe,列访问选通脉冲)请求。注意,RAS和CAS请求共享相同的DRAM地址引脚。
- 要取出内存地址A处的一个字,内存控制器将A转换成一个超单元地址,并将它发送到内存模块,然后内存模块再将和广播道每个DRAM。作为响应,每个DRAM输出它的超单元的8位内容。模块中的电路手机这些输出,并把它们合并成一个64位字,再返回给内存控制器。
-
增强的DRAM
- 快页模式DRAM(Fast Page Mode DRAM,FPM DRAM)。
- 扩展数据输出DRAM(Extended Data Out DRAM,EDO DRAM)。FPM DRAM的一个增强的形式。
- 同步DRAM(Synchronous DRAM,SDRAM)。
- 双倍数据速率同步DRAM(Double Data-Rate Synchronous DRAM,DDR SDRAM),是对SDRAM的一种增强。
- 视频RAM(Video RAM,VRAM)。
-
非易失性存储器
- PROM(Programmable ROM,可编程ROM)只能被编程一次。
- 可擦写可编程ROM(Erasable Programmable ROM,EPROM)。
- 电子可擦除PROM(Electrically Erasable PROM,EEPROM)类似于EPROM,但是它不需要一个物理上独立的编程设备,
- 闪存(flash memory)是一类非易失性存储器,基于EEPROM,它已经成为了一种重要的存储技术。
- 存储在ROM设备中的程序通常被称为固件(firmware)
-
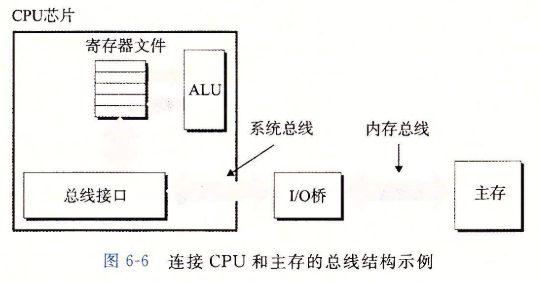
访问内存
- 数据流通过称为总线(bus)的共享电子电路在处理器和DRAM主存之间来来回回。每次CPU和主存之间的数据传送都是通过一系列步骤来完成的,这些步骤称为总线事务(bus transaction)。
- 读事务(read transaction)从主存传送数据到CPU。
- 写事务(write transaction)从CPU传送数据到主存。
-
6.1.2 磁盘存储
- 磁盘是广为应用的保存大量数据的存储设备,存储数据的数量级可以达到几百到几千兆字节,而基于RAM的存储器只能有几百或几千兆字节。不过,从磁盘上读信息的时间为毫秒级,比从DRAM读慢了10万倍,比从SRAM读慢了100万倍。
1.磁盘构造

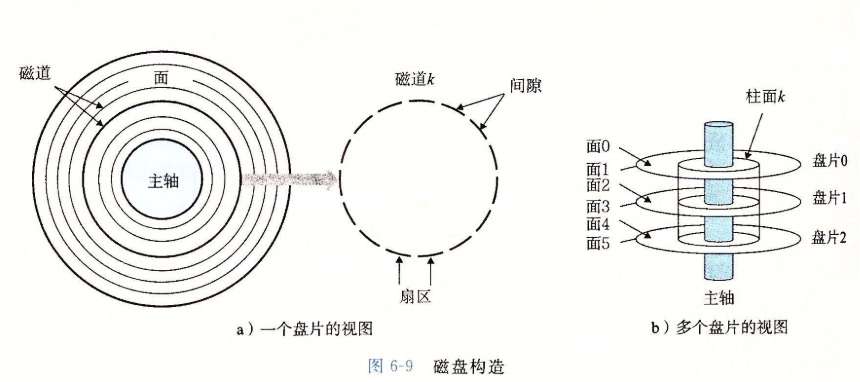
2. 磁盘容量
- 一个磁盘上可以记录的最大位数称为它的最大容量,或者简称为容量。磁盘容量是由以下技术因素决定的:


3.磁盘操作
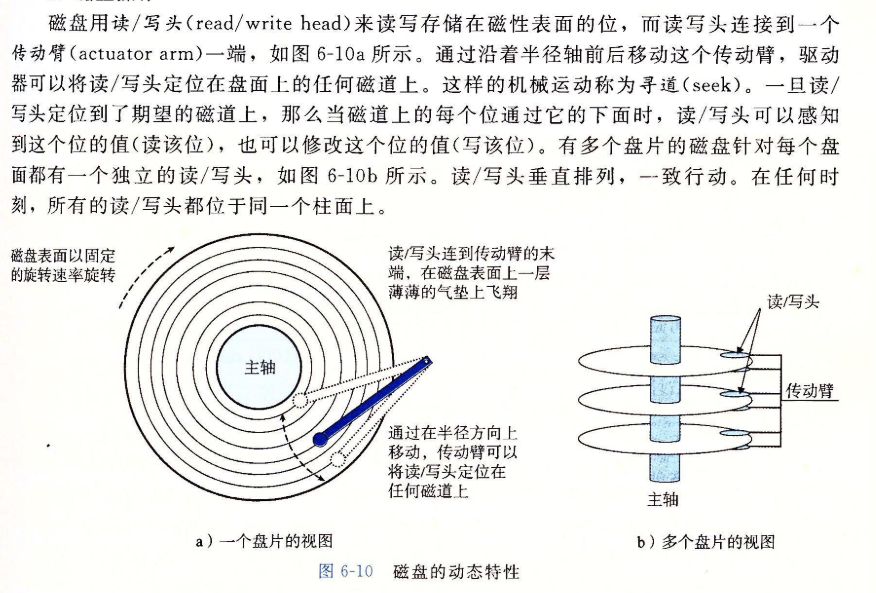
-
磁盘以扇区大小的块来读写数据。对扇区的访问时间(access time)有三个主要的部分:寻道时间(seek time)、旋转时间(rotational latency)和传送时间(transfer time):



-
我们可以估计访问一个磁盘扇区内容的平均时间为平均寻道时间、平均旋转延迟和平均传送时间之和。

4.逻辑磁盘块
- 一个B个扇区大小的逻辑块的序列,编号为0,1,…,B-1。磁盘封装中有一个小小的硬件/固件设备,称为磁盘控制器,维护者逻辑块号和实际(物理)磁盘扇区之间的映射关系。
- 当操作系统想要执行一个I/O操作时,例如读一个磁盘扇区的数据到主存,操作系统会发送一个命令到磁盘控制器,让它读某个逻辑块号。控制器上的固件执行一个快速表查找,将一个逻辑块号翻译成一个(盘面,磁道,扇区)的三元组,这个三元组唯一地标识了对应的物理扇区。
5. 连接I/O设备
6. 访问磁盘
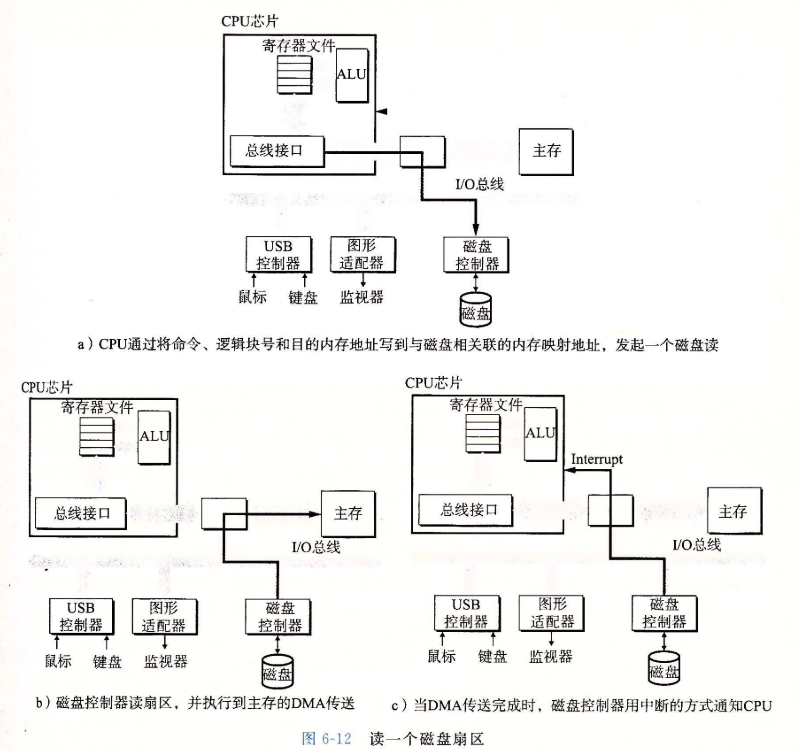
6.1.3 固态硬盘
- 读SSD比写要块。随机读和写的性能差别是由底层闪存基本属性决定的。
- 如图6-13所示,一个闪存由B个块的序列组成,每个块由P页组成。
- 只有在一页所属的块整个被擦除之后,才能写这一页(通常是指该块中的所有位都被设置为1)。
6.2 局部性
- 一个编写良好的计算机程序常常具有良好的局部性(locality)。也就是,它们倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。这种倾向性,被称为局部性原理(principle of locality)。
- 局部性通常有两种不同的形式:时间局部性(temporal locality)和空间局部性(spatial locality)。
- 在一个具有良心时间局部性的程序中,被引用过一次的内存位置很可能在不远的将来再被多次引用。
- 再一个具有良好的空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能再不远的将来引用附近的一个内存位置。
- 一般而言,有良好局部性的程序比局部性差的程序运行得更快。
6.2.1 对程序数据引用的局部性
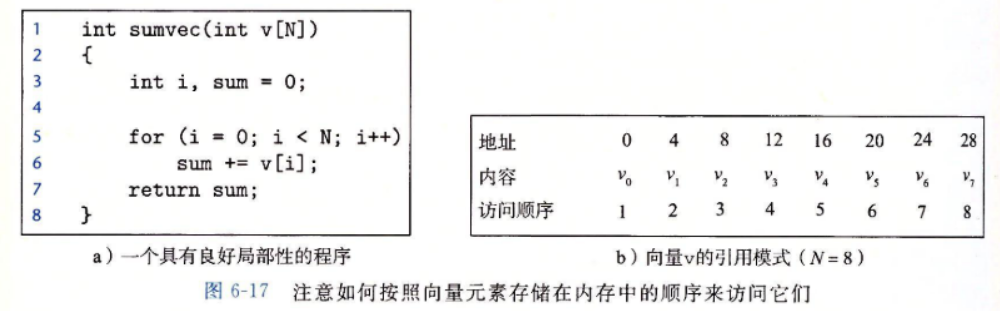
-
像sumvec这样顺序访问一个向量每个元素的函数,具有步长为1的引用模式(stride-1 reference pattern)(相对于元素的大小)。有时我们称步长为1的引用模式为顺序引用模式(sequential reference pattern)。一个连续向量中,每隔k个元素进行访问,就称为步长为k的引用模式(stride-k reference pattern)。步长为1的引用模式是程序中空间局部性常见和重要的来源。一般而言,随着步长的增加,空间局部性下降。
-
考虑图6-18a中的函数sumarrayrows,它对一个二维数组的元素求和。双重嵌套循环按照行优先顺序(row-major order)读数组的元素。
- 其结果是得到一个很好的步长为1的引用模式,具有良好的空间局部性。

-
交换了i和j的循环,局部性变得很差:

6.2.2 取指令的局部性
6.2.3 局部性小结

6.3 存储器层次结构
-
硬件和软件的这些基本属性互相补充得很完美。它们这种相互补充的性质使人联像到一种组织存储器系统的方法,称为存储器层次结构(memory hierarchy)。
-
一般而言,从高层往底层走,存储设备变得更慢、更便宜和更大。
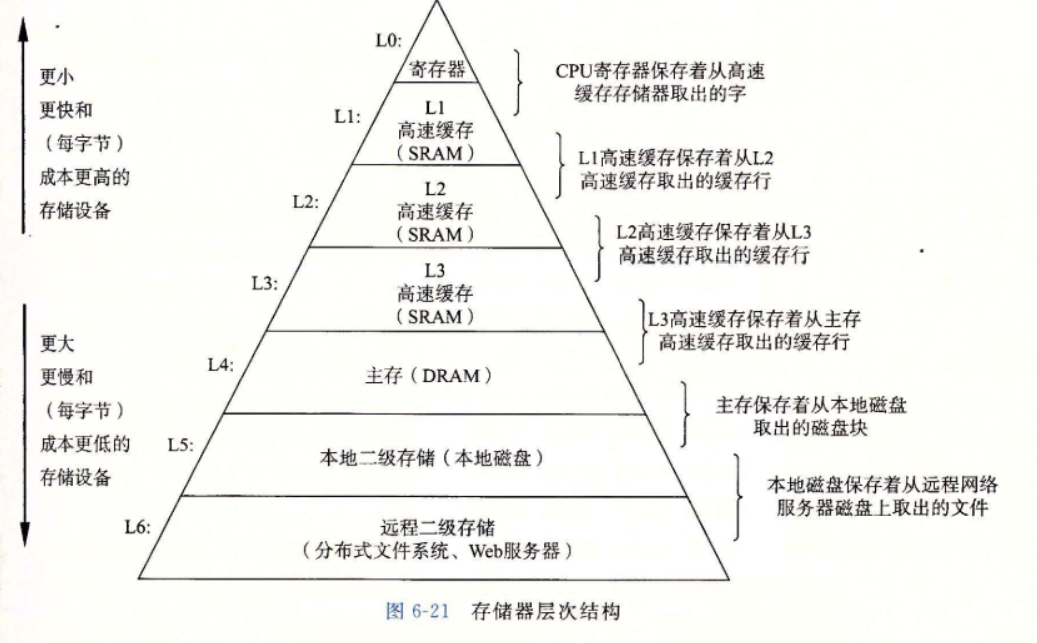
6.3.1 存储器层次结构中的缓存
-
一般而言,高速缓存(cache,读作“cash”)是一个小而快速的存储设备,它作为存储在更大、也更慢的设备中的数据对象的缓冲区域。
-
使用高速缓存的过程称为缓存(caching,读作“cashing”)。
-
存储器层次结构的中心思想是,对于每个k,位于k层的更小更快的存储设备作为位于k+1层的更大更慢的存储设备的缓存。
-
图6-22展示了存储器层次结构中缓存的一般性概念。第k+1层的存储器被划分成连续的数据对象组块(chunk),称为块(block)。
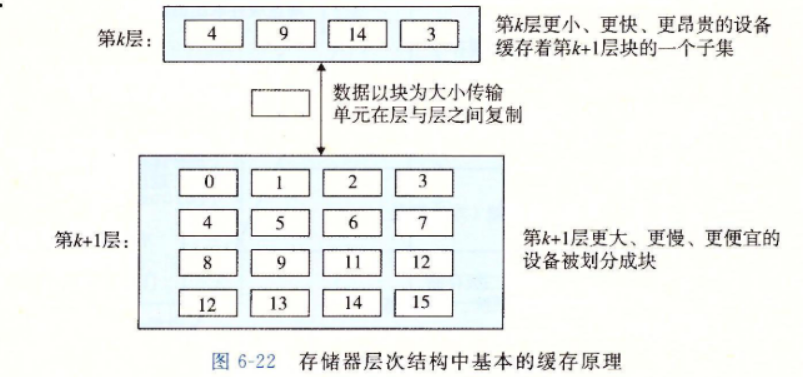
-
数据总是以块大小为传送单元(transfer unit)在第k层和第k+1层之间来回复制的。
1.缓存命中
- 当程序需要第k+1层的某个数据对象d时,它首先在当前存储在第k层的一个块中查找d。如果d刚好缓存在第k层中,那么就是我们所说的缓存命中(cache hit)。
2.缓存不命中
- 另一方面,如果第k层中没有缓存数据对象d,那么就是我们所说的缓存不命中(cache miss)。
- 当发生缓存不命中时,第k层的缓存从第k+1层缓存中取出包含d的那个块,如果第k层的缓存已经满了,可能就会覆盖一个现存的块。
- 覆盖一个现存的块的过程称为替换(replace)或驱逐(evicting)这个块。被驱逐的这个块有时也称为牺牲块(victim block)。决定该替换哪个块是由缓存的替换策略(replacement policy)来控制的。例如,一个具有随机替换策略的缓存会随机选择一个牺牲块。一个具有最近最少被使用(LRU)替换策略的缓存会选择那个最后被访问的时间距现在最远的块。
3.缓存不命中的种类
- 如果第k层的缓存时空的,那么对任何数据对象的访问都不会命中。一个空的缓存有时被称为冷缓存(cold cache),此类不命中被称为强制性不命中(compulsory miss)或冷不命中(cold miss)。
- 只要发生了不命中,第k层的缓存就必须执行某个放置策略(placement policy)。
- 硬件缓存通常使用的是更严格的放置策略。
- 限制性的放置策略会引起一种不命中,称为冲突不命中(conflict miss)。
4.缓存管理
6.4 高速缓存存储器
高速缓存存储器的典型总线结构
6.4.1 通用的高速缓存存储器组织结构
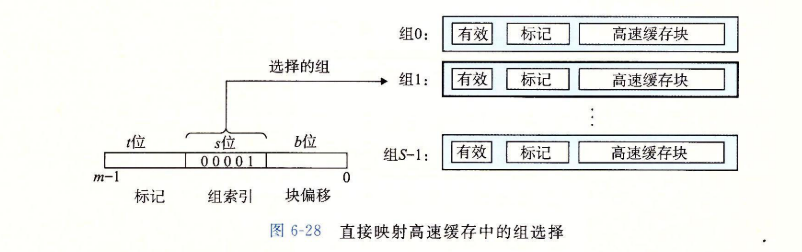
-
考虑一个计算机系统,其中每个存储器地址有位,形成个不同的地址。如图6-25a所示,这样一个机器的高速缓存被组织成一个有个高速缓存组(cache set)的数组。每个组包含个高速缓存行(cache line)。每个行是由一个字节的数据块(block)组成的。一个有效位(valid bit)指明这个行是否包含由意义的信息,还有个标记位(tag bit)( 集),它们唯一地标识存储在这个高速缓存行的块。
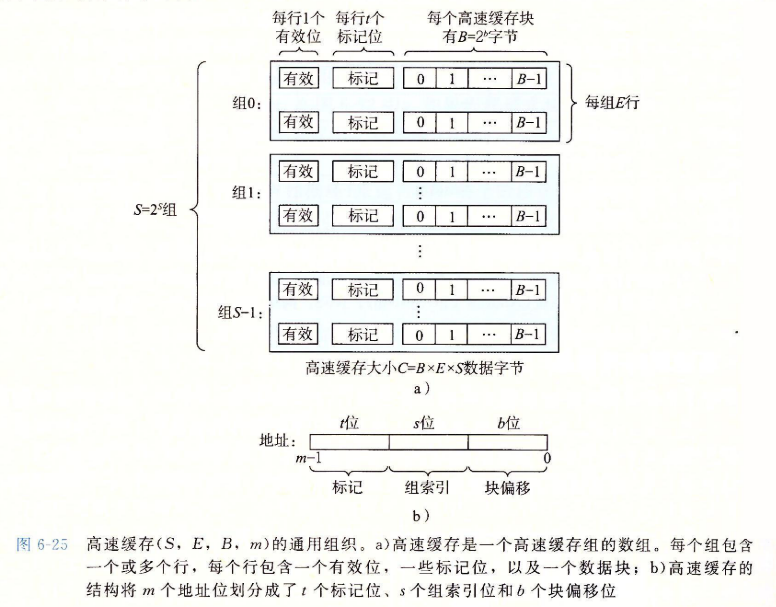
-
一般而言,高速缓存的结构可以用元组来描述。高速缓存的大小(或容量)指的是所有块的大小的和。标记位和有效位不包括在内。因此,。

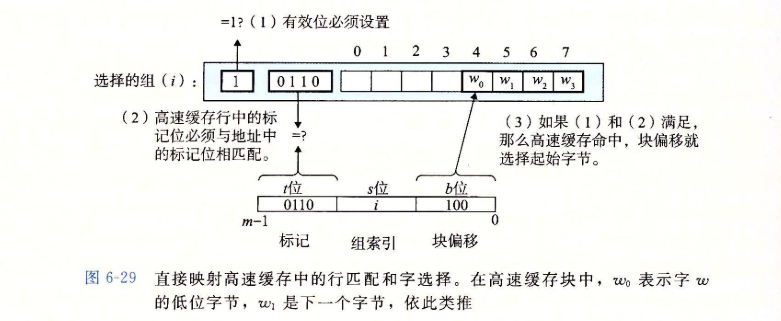
6.4.2 直接映射高速缓存
-
每个组只有一行()的高速缓存被称为直接映射高速缓存(direct-mapped cache)。
-
抽取初被请求的字的过程,分为三步:
- 组选择
- 行匹配
- 字抽取
-
“抖动”:高速缓存反复地加载和驱逐相同的高速缓存块的组。
-
如果高位用做索引,那么一些连续的内存块就会映射到相同的高速缓存块。
- 相较而言,以中间位作为索引,相邻的块总是映射到不同的高速缓存行。
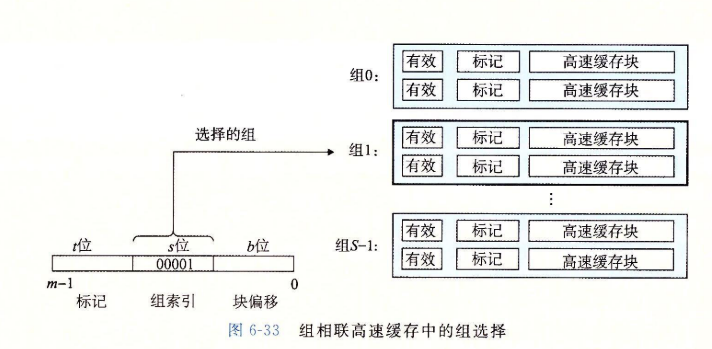
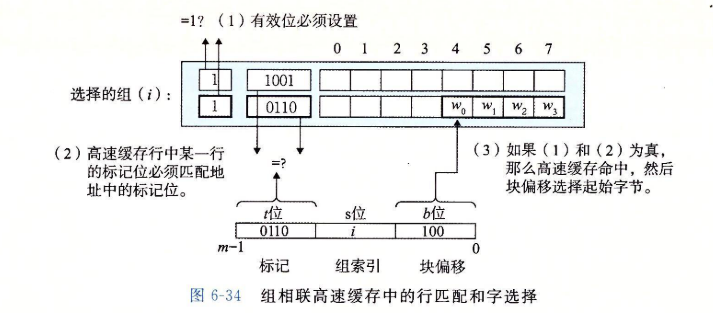
6.4.3 组相连高速缓存
-
组相连高速缓存(set associative cache)每个组都有保存由多于一个的高速缓存行。
-
它的组选择与直接映射高速缓存的组选择一样,组索引位标识组。
-
组相连高速缓存的行匹配比直接映射高速缓存中的更复杂,因为它必须检查多行的标记位和有效位,以确定所请求的字是否在集合中。
组相连高速缓存中不命中时的行替换
-
最简单的替换策略时随机选择要替换的行。
-
其他更复杂发策略利用了局部性原理,以使在比较近的将来引用被替换的行的概率最小。例如,
- 最不常使用(Least-Frequently-Used,LFU)策略会替换在过去某个时间窗口内引用次数最少的那一行。
- 最近最少使用(Least-Recently-Used,LRU)策略会替换最后一次访问时间最久远的那一行。
所有这些策略都需要额外的时间和硬件。
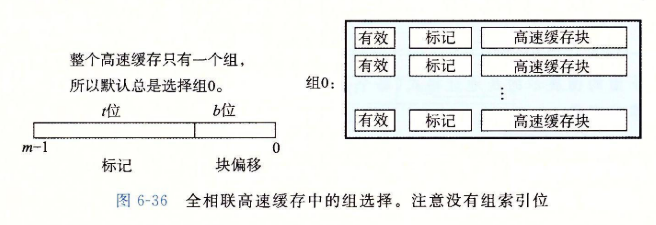
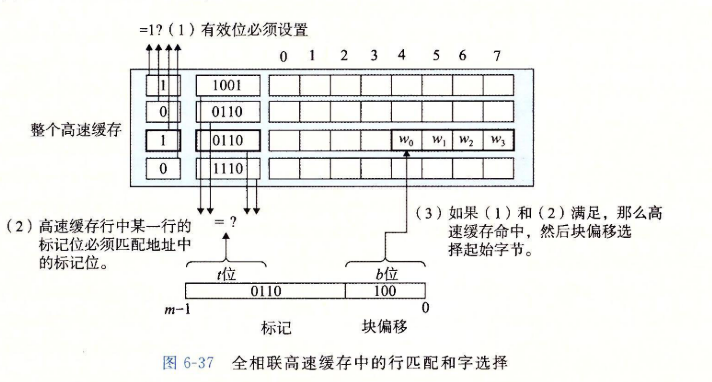
6.4.4 全相联高速缓存
-
全相联高速缓存(fully associative cache)是由一个包含所有高速缓存行的组(即)组成的。
-
全相联高速缓存中的组选择非常简单,因为只有一个组,地址中没有组索引位,地址只被划分成了一个标记和一个块偏移。
-
全相联高速缓存只适合做小的高速缓存。
6.4.5 有关写的问题
- 高速缓存关于读的操作非常简单。首先,在高速缓存中查找所需字的副本。如果命中,立即返回字给CPU。如果不命中,从存储器层次结构中较低层中取出包含字的块,将这个块存储到某个高速缓存行中(可能会驱逐一个有效的行,然后返回字)。
写的情况就要复杂一些了:

6.4.6 一个真实的高速缓存层次结构的解剖
- 既保存指令又包括数据的高速缓存称为统一的高速缓存(unified cache)
6.4.7 高速缓存参数的性能影响
- 有许多指标来衡量高速缓存的性能:

- 高速缓存大小的影响

-
块大小的影响

-
相联度的影响

-
写策略的影响


6.5 编写高速缓存友好的代码
- 让最常见的情况运行得快。
- 尽量减小每个循环内部的缓存不命中数量。
6.6 综合:高速缓存对程序性能的影响
6.6.1 存储器山
6.6.2 重新排列循环以提高空间局部性
6.6.3 在程序中利用局部性
6.7 小结
第7章 链接
本博客所有文章除特别声明外,均为博客作者本人编写整理,转载请联系作者!