生产者-消费者问题的C语言实现
实验六 生产者-消费者问题实现
实验题目
要求
-
在Linux操作系统下用C实现经典同步问题:生产者—消费者,具体要求如下:
(1) 一个大小为10的缓冲区,初始状态为空。
(2) 2个生产者,随机等待一段时间,往缓冲区中添加数据,若缓冲区已满,等待消费者取走数据之后再添加,重复10次。
(3) 2个消费者,随机等待一段时间,从缓冲区中读取数据,若缓冲区为空,等待生产者添加数据之后再读取,重复10次。
提示
-
本实验的主要目的是模拟操作系统中进程同步和互斥。在系统进程并发执行异步推进的过程中,由于资源共享和进程间合作而造成进程间相互制约。进程间的相互制约有两种不同的方式。
(1)间接制约。这是由于多个进程共享同一资源(如CPU、共享输入/输出设备)而引起的,即共享资源的多个进程因系统协调使用资源而相互制约。
(2)直接制约。只是由于进程合作中各个进程为完成同一任务而造成的,即并发进程各自的执行结果互为对方的执行条件,从而限制各个进程的执行速度。 -
生产者和消费者是经典的进程同步问题,在这个问题中,生产者不断的向缓冲区中写入数据,而消费者则从缓冲区中读取数据。生产者进程和消费者对缓冲区的操作是互斥,即当前只能有一个进程对这个缓冲区进行操作,生产者进入操作缓冲区之前,先要看缓冲区是否已满,如果缓冲区已满,则它必须等待消费者进程将数据取出才能写入数据,同样的,消费者进程从缓冲区读取数据之前,也要判断缓冲区是否为空,如果为空,则必须等待生产者进程写入数据才能读取数据。
-
在本实验中,进程之间要进行通信来操作同一缓冲区。一般来说,进程间的通信根据通信内容可以划分为两种:即控制信息的传送与大批量数据传送。有时,也把进程间控制信息的交换称为低级通信,而把进程间大批量数据的交换称为高级通信。目前,计算机系统中用得比较普遍的高级通信机制可分为3大类:共享存储器系统、消息传递系统及管道通信系统。
- 共享存储器系统:共享存储器系统为了传送大量数据,在存储器中划出一块共享存储区,诸进程可通过对共享存储区进行读数据或写数据以实现通信。进程在通信之前,向系统申请共享存储区中的一个分区,并为它指定一个分区关键字。
- 消息传递系统:在消息传递系统中,进程间的数据交换以消息为单位,在计算机网络中被称为报文。消息传递系统的实现方式又可以分为以下两种:
- 直接通信方式:发送进程可将消息直接发送给接收进程,即将消息挂在接收进程的消息缓冲队列上,而接收进程可从自己的消息缓冲队列中取得消息。
- 间接通信方式:发送进程将消息发送到指定的信箱中,而接收进程从信箱中取得消息。这种通信方式又称信箱通信方式,被广泛地应用于计算机网络中。相应地,该消息传递系统被称为电子邮件系统。
- 管道通信系统:向管道提供输入的发送进程,以字符流方式将大量的数据送入管道,而接收进程从管道中接收数据。由于发送进程和接收进程是利用管道进行通信的,故称为管道通信。为了协调发送和接收双方的通信,管道通信机制必须提供以下3方面的协调功能:
- 互斥:当一个进程正在对pipe文件进行读或写操作时,另一个进程必须等待。
- 同步:当写进程把一定数量的数据写入pipe文件后,便阻塞等待,直到读进程取走数据后,再把写进程唤醒。
- 确认对方是否存在:只有确定对方已存在时,才能进行管道通信,否则会造成因对方不存在而无限制地等待。
-
在这个问题当中,我们采用信号量机制进行进程之间的通信,设置两个信号量,空的信号量和满的信号量。
-
在Linux系统中,一个或多个信号量构成一个信号量集合。使用信号量机制可以实现进程之间的同步和互斥,允许并发进程一次对一组信号量进行相同或不同的操作。每个P、V操作不限于减1或加1,而是可以加减任何整数。在进程终止时,系统可根据需要自动消除所有被进程操作过的信号量的影响。
- 缓冲区采用循环队列表示,利用头、尾指针来存放、读取数据,以及判断队列是否为空。缓冲区中数组大小为10;
- 利用随机函数rand()得到A~Z的一个随机字符,作为生产者每次生产的数据,存放到缓冲区中;
- 使用
shmget()系统调用实现共享主存段的创建,shmget()返回共享内存区的ID。对于已经申请到的共享段,进程需把它附加到自己的虚拟空间中才能对其进行读写。 - 信号量的建立采用
semget()函数,同时建立信号量的数量。在信号量建立后,调用semctl()对信号量进行初始化,例如本实验中,可以建立两个信号SEM_EMPTY、SEM_FULL,初始化时设置SEM_EMPTY为10,SEM_FULL为0。使用操作信号的函数semop()做排除式操作,使用这个函数防止对共享内存的同时操作。对共享内存操作完毕后采用shmctl()函数撤销共享内存段。 - 使用循环,创建2个生产者以及2个消费者,采用函数fork()创建一个新的进程。
- 一个进程的一次操作完成后,采用函数
fflush()刷新缓冲区。 - 程序最后使用
semctl()函数释放内存。
模拟程序的程序流程图
-
主程序流程图:
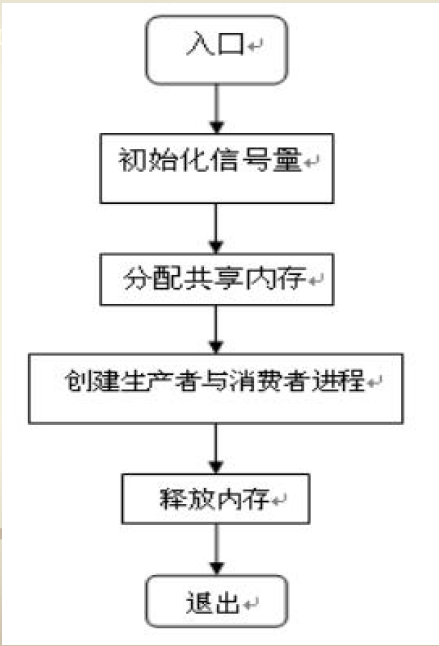
-
生产者进程流程图
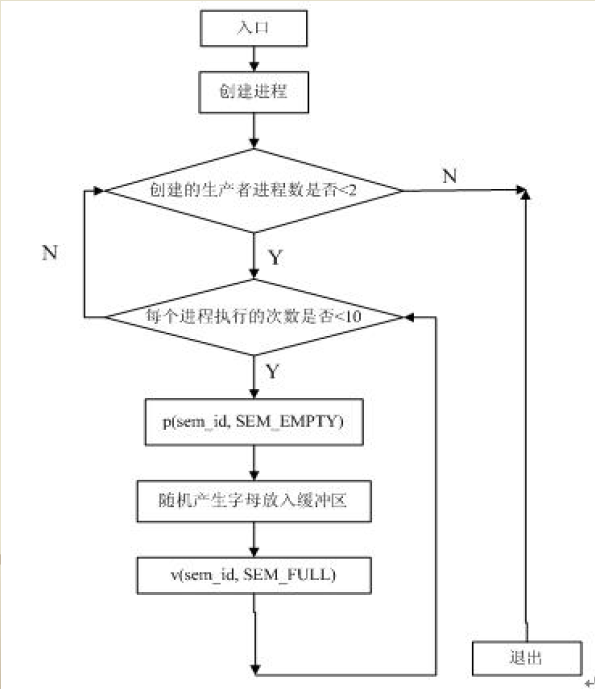
-
消费者进程流程图
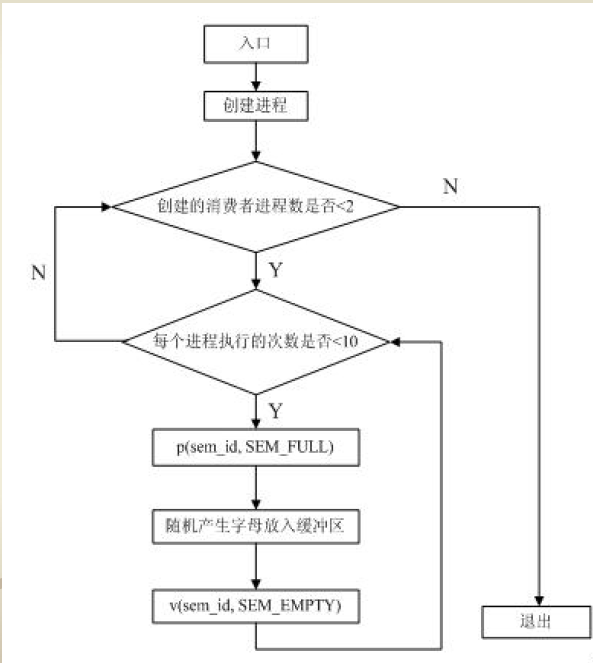
-
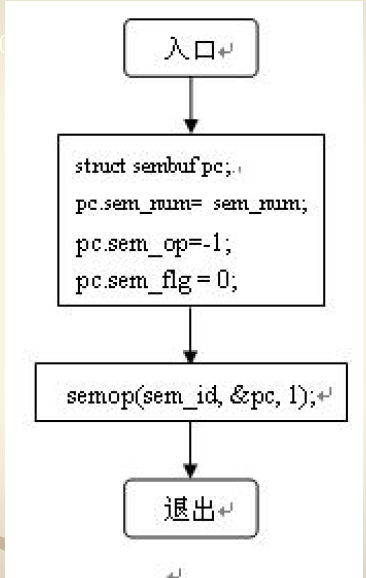
P操作流程图
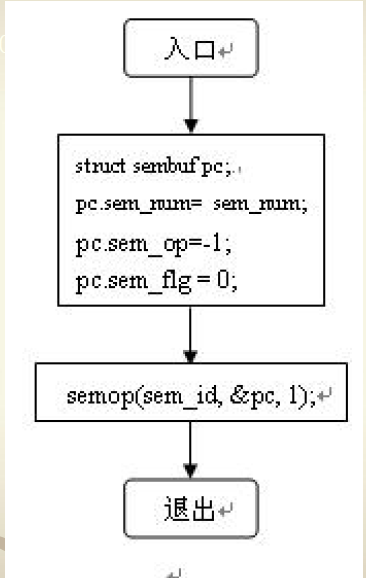
-
V操作流程图
程序中使用的数据结构及符号说明
-
自定义结构体
buf:实现循环队列1
2
3
4
5
6
7
8
9struct buf //循环队列
{
int in; //指向缓冲中下一个空位
int out; //指向缓冲中第一个满位
char str[MAX_BUFFER_SIZE]; //存放字母
int num; //产品个数
int is_empty; //是否为空
};
struct buf *bf; //定义一个循环队列指针 -
库
<sys/time.h>中的结构体timeval:实现时间1
2
3
4
5
6
7
8
9/*
struct timeval
{
time_t tv_sec; //seconds
suseconds_t tv_usec; //icroseconds
};
*/
struct timeval start; //开始时间
struct timeval now; //当前时间 -
库
<sys/sem.h>中的结构体sembuf:对信号量操作1
2
3
4
5
6
7
8
9/*
struct sembuf
{
unsigned short int sem_num; //信号量编号
short int sem_op; //对信号量的操作
short int sem_flg; //通常设为SEM_UNDO
}
*/
struct sembuf sb; -
整型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//缓冲区大小
#define MAX_BUFFER_SIZE 10
//共享内存和信号量:当前用户的进程可读写
#define SHM_MODE 0600
#define SEM_MODE 0600
//信号量的键值
#define SEM_FULL 1 //信号量 1 --- full
#define SEM_EMPTY 2 //信号量 2 --- empty
#define MUTEX 3 //信号量 3 --- 互斥量
//共享内存的键值
#define SHMKEY 75
const int N_Consumer = 2; //消费者数量
const int N_Producer = 2; //生产者数量
const int N_Buffer = 10; //缓冲区大小
const int N_Worktime = 10; //每个进程执行的次数
int shm_id; //shmget函数返回的共享内存标识符
int full, empty, mutex; //semget函数返回的信号量标识符 -
void指针
1
void *addr; //地址指针,连接共享内存段的地址空间 -
自定义函数(实现详见下方代码):
1
2
3
4
5
6
7int get_rand_num() //0~99 随机数
char get_rand_letter() //随机生成A~Z
void Wait(int sem_id) //P操作
void Signal(int sem_id) //V操作
void printTime() //输出时间
void Producer(struct buf *bf) //生产者操作
void Consumer(struct buf *bf) //消费者操作 -
各类库中的关键函数
-
<sys/shm.h>中:-
shmget()函数:用来创建共享内存。1
int shmget(key_t key, size_t size, int shmflg);- 第一个参数:键值key有效地为共享内存段命名。
- 第二个参数:size以字节为单位指定需要共享的内存容量。
- 第三个参数:shmflg是权限标志,如果要想在key标识的共享内存不存在时创建,需要与IPC_CREAT做或操作。如0644,它表示允许一个进程创建的共享内存被内存创建者所拥有的进程向共享内存读取和写入数据,同时其他用户创建的进程只能读取共享内存。
- 调用成功时返回一个与key相关的共享内存标识符(非负整数),用于后续的共享内存函数。调用失败返回-1.
-
shmat()函数:启动对该共享内存的访问,并把共享内存连接到当前进程的地址空间。1
void *shmat(int shm_id, const void *shm_addr, int shmflg);- 第一个参数:shm_id是由shmget()函数返回的共享内存标识。
- 第二个参数:shm_addr指定共享内存连接到当前进程中的地址位置,通常为空,表示让系统来选择共享内存的地址。
- 第三个参数:shm_flg是一组标志位,通常为0。
- 调用成功时返回一个指向共享内存第一个字节的指针,如果调用失败返回-1。
-
shmdt()函数:用于将共享内存从当前进程中分离。1
int shmdt(const void *shmaddr);- 参数:shmaddr是shmat()函数返回的地址指针。
- 调用成功时返回0,失败时返回-1。
-
shmctl()函数:用来控制共享内存。1
int shmctl(int shm_id, int command, struct shmid_ds *buf);- 第一个参数:shm_id是shmget()函数返回的共享内存标识符。
- 第二个参数:command是要采取的操作,它可以取下面的三个值:
- IPC_STAT:把shmid_ds结构中的数据设置为共享内存的当前关联值,即用共享内存的当前关联值覆盖shmid_ds的值;
- IPC_SET:如果进程有足够的权限,就把共享内存的当前关联值设置为shmid_ds结构中给出的值;
- IPC_RMID:删除共享内存段。
- 第三个参数:buf是一个结构指针,它指向共享内存模式和访问权限的结构。
- 调用成功时返回0,失败时返回-1。
-
-
<sys/sem.h>中:-
semget()函数:创建一个新的信号量集1
int semget(key_t key,int nsems,int semflg);- 第一个参数:键值key有效地为信号量(集)命名。
- 第二个参数:一个新的信号量集中应该创建的信号量的个数。单个信号量则为1。
- 第三个参数:权限位,如果要想在key标识的信号量不存在时创建,需要与IPC_CREAT做或操作。
- 调用成功则返回信号量集的IPC标识符,失败则返回-1。
-
semctl()函数:用来控制信号量1
int semctl(int semid,int semnum,int cmd,union semun arg);-
第一个参数:sem_id是semget()函数返回的信号量标识符。
-
第二个参数:semnum是信号量编号,当要用到信号量集时才用到。单个信号量则为0。
-
第三个参数:cmd是要采取的操作,它可以取下面的几个值:
-
IPC_STAT(或STAT):获得该信号量(或信号量集)的semid_ds结构(描述信号量的结构),并存放在第四个参数arg结构变量的buf域指向的semid_ds结构中。
-
IPC_SETVAL(或SETVAL):将信号量值设置为arg的值。
-
IPC_GETVAL (或GETVAL):返回信号量的当前值。
-
IPC_RMID:删除信号量。
-
-
调用成功时根据cmd值的不同返回不同值,失败时返回-1。
-
-
semop()函数:对信号量进行操作1
int semop(int semid,struct sembuf*sops,size_t nsops );-
第一个参数:sem_id是semget()函数返回的信号量标识符。
-
第二个参数:sops指向信号量操作结构体。
1
2
3
4
5
6struct sembuf
{
unsigned short int sem_num; //信号量编号
short int sem_op; //对信号量的操作(-1:P +1:V)
short int sem_flg; //通常设为SEM_UNDO
} -
第三个参数:nsop是sops中的操作个数,通常为1,代表单个操作。
-
调用成功时返回信号量标识符,失败时返回-1。
-
-
-
源程序并附上注释
1 | |
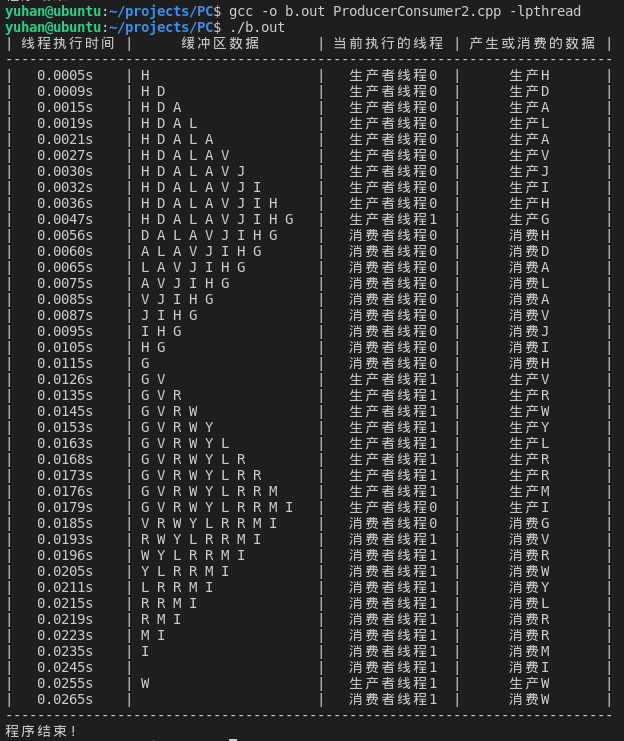
运行结果

思考题
以上是通过进程来实现生产者和消费者问题,考虑如何采用线程来实现。
- 相比于进程实现,线程实现有以下几个不同:
- 进程实现主要使用fork()来实现创建进程,而线程实现主要使用库<pthread.h>来实现线程。
- 线程间通信无需共享内存,故无需库<sys/shm.h>,循环数组buf也不需要定义成指针指向地址空间。
- 进程的信号量通过库<sys/sem.h>实现,而线程的信号量是通过库<semaphore.h>实现的。
主要的库函数
-
<pthread.h>中:
-
pthread_t:声明线程标识符。 -
pthread_create()函数:用于创建线程。1
int pthread_create(pthread_t *tidp,const pthread_attr_t *attr,void *(*start_rtn)(void*),void *arg);- 第一个参数是指向线程标识符的指针。
- 第二个参数指定各种不同的线程属性,可以为NULL。
- 第三个参数是线程运行函数的起始地址。
- 第四个参数是运行函数的参数。
-
pthread_join用来等待一个线程的结束,线程间同步的操作1
int pthread_join(pthread_t thread, void **retval);- 第一个参数为线程标识符,即线程ID。
- 第二个参数retval为用户定义的指针,用来存储线程的返回值。
-
-
<semaphore.h>中:
-
sem_t:信号量的数据类型。 -
sem_init()函数:信号量初始化1
sem_init(sem_t *sem, int pshared, unsigned int value);- 第一个参数*sem是对应的信号量。
- 第二个参数pshared:0表⽰线程间共享,非0表示进程间共享。
- 第三个参数value是信号量初值,大于0表示才可以访问。
-
sem_wait()函数:P操作。1
int sem_wait(sem_t *sem); -
sem_post()函数:V操作1
int sem_post(sem_t *sem);
-
源程序并附上注释
1 | |
运行结果
实验总结和心得
-
开始看到这个实验的题目时,头绪不多。因为所需要用到的Linux相关库
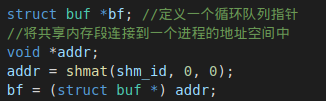
<sys/shm.h>、<sys/sem.h>是之前没有接触过的。之后我通过查找资料,更好地了解如何使用它们实现生产者-消费者问题,具体使用的库函数可详见我上方的实验报告。这个过程中踩的一些坑被我记录下来:- 要额外定义一个void指针addr保存shmat的返回值,直接用循环队列指针*bf保存会导致类型不匹配。
-
刚开始运行时提示错误“共享内存创建失败”。

-
这是因为创建共享内存的函数的第三个参数没有或上
IPC_CREAT。
-
-
如何打印缓冲区中的数据是需要细心考虑的:
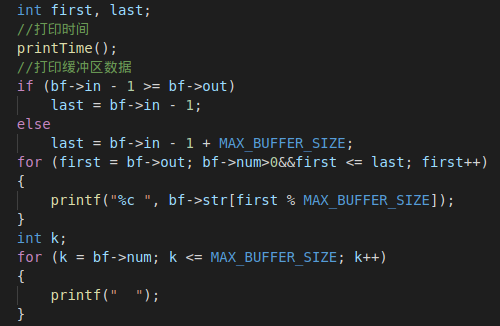
- in记录的是缓冲中下一个空位,in-1就是缓冲中最后一个满位。out记录的缓冲中第一个满位。对于一个表示缓冲区的循环队列(数组实现),in-1可能在out“前面”,即
in-1<out。这时就需要将last赋值为in-1+MAX_BUFFER_SIZE,做% MAX_BUFFER_SIZE后就可指向缓冲区数组的正确位置。
- in记录的是缓冲中下一个空位,in-1就是缓冲中最后一个满位。out记录的缓冲中第一个满位。对于一个表示缓冲区的循环队列(数组实现),in-1可能在out“前面”,即
-
时间的处理主要用到
timeval结构体,在前文也已进行说明。错误提示输出perror()和较美观的输出界面体现了人性化设计。 -
整个问题的实现可以由实验指导书的流程图较好地被标示出来,理解了这几个流程后,多点耐心、细心就可以完成代码实现。
-
对于思考题中的线程实现,则需要去了解库
<pthread.h>和<semaphore.h>。整体框架和进程实现大同小异,不同点在思考题已做说明。 -
总的来说,这次实验让我对生产者-消费者问题的实现和基于Linux环境的C语言编程有了更加深刻的了解,较好地锻炼了我的逻辑思维和代码设计能力。
参考链接
- 《【操作系统实验】Linux环境下用进程实现生产者消费者问题——C语言完整代码+详细实验报告》:https://blog.csdn.net/qq_44528283/article/details/114801233
本博客所有文章除特别声明外,均为博客作者本人编写整理,转载请联系作者!